

Navigating the Future: Tech in Venture Capital
Navigating the Future: Tech in Venture Capital
Why AI Will Bring the "Tinder Moment" to VC

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Tuesday, I publish “Insights” to digest the most relevant startup research & reports, and every Thursday, I publish “Essays” that cover hands-on insights about data-driven innovation and AI in venture capital. Follow along to understand how startup investing becomes more data-driven, why it matters, and what it means for you.
Current subscribers: 18,220, +505 since last week
Brought to you by VESTBERRY - Portfolio Intelligence Platform for data-driven VCs

Data Engineering is no longer just a backstage player but is taking center stage in the VC space. It is about constructing and maintaining the architectures (think databases, large-scale processing systems) that allow for data availability—a cornerstone for insightful analysis and well-informed decisions.
Turning raw data into usable outputs and insights has great use cases for deal sourcing, due diligence, or portfolio monitoring. Dive deeper into this video, where we break down the impact of data engineering on the VC industry.
The importance of technology and AI in VC cannot be underestimated. Our industry is undergoing a massive transformation and by now, every investor should know. 2017, when I got into VC, few people thought about this topic. And certainly, nobody openly spoke about it.
Times have changed, and over the past 6 to 7 years I’m lucky to be part of a growing Data-driven VC community where we exchange thoughts and learnings in small trusted groups. Behind closed doors.
What databases do you use? How can you spot stealth founders? Deduplication? Entity resolution? Which CRM is the best? Make vs buy? What profile to hire as your first engineer? How can you differentiate if every fund has access to the same data?
These and many more questions have been on the agenda. Last Thursday, we decided to open doors for one of these groups, and on Francesco Petricarari and Ralph King’s initiative, we ran an online panel.
650+ signups, 400+ participants, and tons of content for 1 hour time. Today, I’m happy to share the recording and key takeaways.

Participants
Mike Arpaia - Moonfire (middle right)
Francesco Corea - Greycroft (bottom left)
Stephane Nasser - OpenVC (bottom right)
Philipp Omenitsch - Sequel (top left)
Danish Abdullah - hive.one (middle left)
Ralph King - Silicon Roundabout Ventures (center)
MC: Francesco Perticarari - Silicon Roundabout Ventures (top right)
… and myself 👋🏻
VC Will Never Be Fully Automated - Will It?
Fra kicked off with a spicy thesis: VC will never be fully automated. Ever. It’s technically unfeasible to automate everything end-to-end. I couldn’t resist but challenge it. I feel that it depends on the setup of the fund. Certainly, it’s true for funds with a lead investor strategy. Someone needs to set the terms, negotiate, do all this human-to-human stuff. Moreover, founders don’t want an algorithm on their board. Sure, I get it.
But what about follower funds? I’m convinced we’ll soon see a cohort of pure quant funds following human-led or augmented VC firms. We can already predict the likelihood of success for private companies and by cutting the wheat from the chaff, algorithms might be able to generate alpha. Even more obvious, a tier1 fund leading the round might increase confidence in the positive trajectory of the company.
The big question for pure quant funds however becomes access? Easy money, but what else? Why should the best founders take your money? This is a question that surely the quant funds will find an answer to.
Philipp adds another dimension: the state of the company. He expects a correlation between the degree of automation and the maturity of the target company. The more mature the startup, the more quantitative data is available, the more work can be automated.
AI Will Bring the “Tinder Moment” to VC
Stephane expects a dating-like situation where all VCs have access to the same data but will eventually get different matches, based on their individual preferences. And not to forget: Someone needs to still go have the date. This will remain all human.
Danish describes the human-algorithm relationship as a second brain. Data-driven capabilities will allow humans to do what they already do, just better and on steroids. Mike adds that DDVC will quickly become a commodity where the human expertise to properly assess opportunities and eventually access competitive deals will be key.
While I agree that access to data might not be a long-term differentiator, I tried to remind everyone that only 1% of all VC firms have internal initiatives to become more data-driven (referring to findings from the Data-driven VC Landscape 2023; survey for 2024 edition open here).
Everyone in this group is part of a tiny bubble and the majority of investors are still stuck in the “Old school” or “Productivity” stages of the VC Digitization journey.
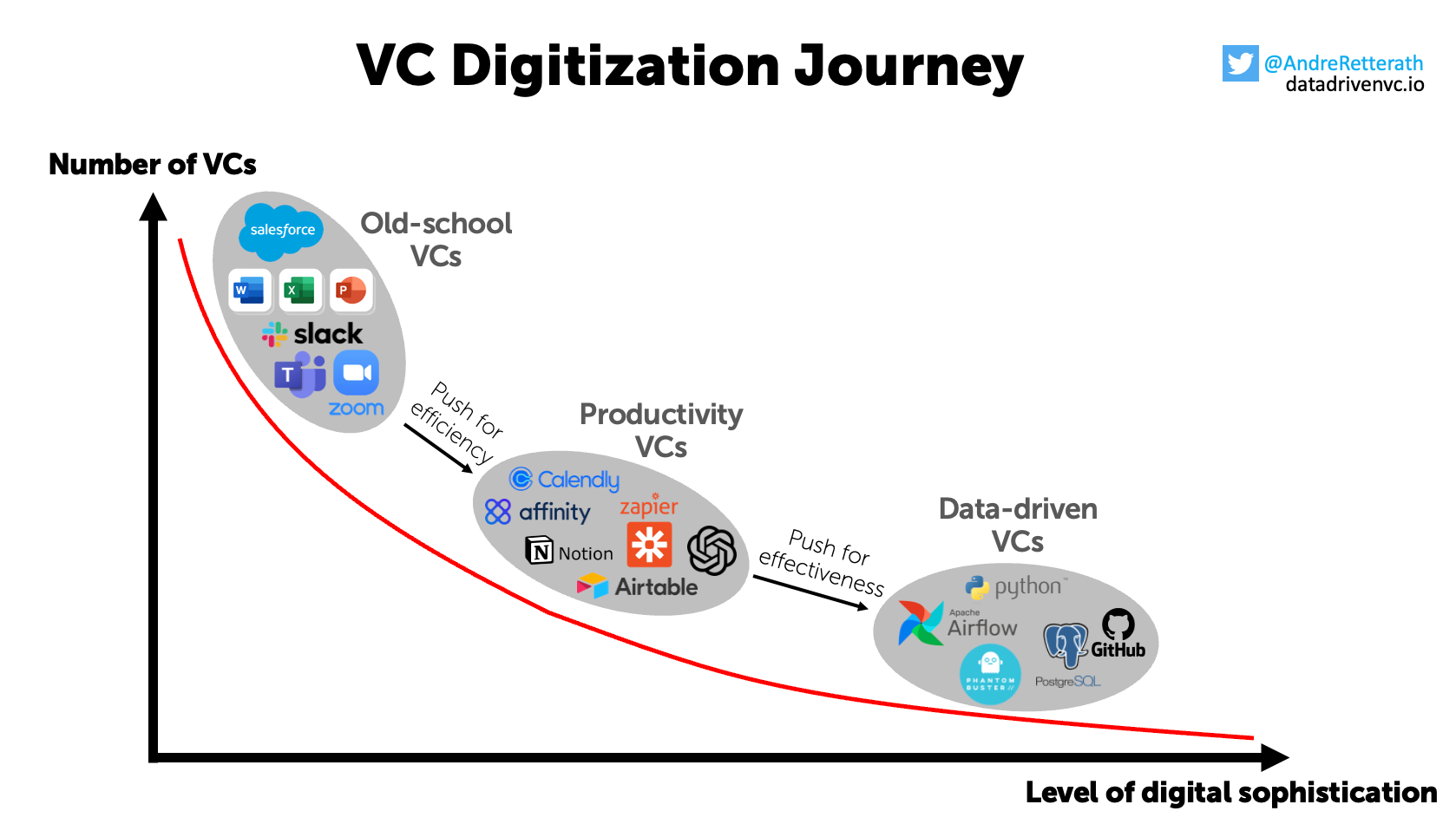
Although I agree that access to data will eventually become a commodity, the time until this happens is probably longer than most of us anticipate. And once we hit this point, differentiation is still possible through proprietary screening algorithms and “taste”, confirming the Tinder analogy made earlier.
Beyond these aspects, differentiation and access is also possible via unique firm brands, personal brands, track records, personal relationships, and more.
Struggles Becoming More Data-Driven
Fra explains that beyond the technical feasibility and access component, firms need to find the right data sources (we’ll publish our new 2024 Database Benchmarking soon, sign up here to get notified), hire good engineering talent to join your firm to properly process and structure all information, to eventually make the insights actionable. Few funds will be able to free up the budgets and streamline all of this. It remains a difficult challenge.
Winning Competitive Deals
Double-clicking on the access component mentioned before, Mike adds that Moonfire uses their platform to generate insights and create value for their portfolio founders. Moving beyond sourcing, screening, and due diligence, and adding data-driven capabilities in the portfolio value creation part of the value chain, will eventually also create higher founder NPS and references that support preferred access. A flywheel initiated by tech.
Philipp brings in another component of access: timing. If you reach out to founders ahead of other VCs, competition might be lower and eventually increase your chances of getting a shot. Fra complements that VCs can augment their human expertise with data-driven insights that investors might share with the founders (such as a competitive landscape) to provide value ahead of a term sheet. Deal-winning skills of the individual professional will still be key.
Mike resumes that there are two categories of deal-winning:
Human-led, tech-augmented traditional winning capabilities
Tech-led, providing access for founders to data-driven insights about their company or leveraging data-driven recruiting tools
His analogy is network-driven sourcing vs data-driven sourcing. There is not one or the other but a combination. For Moonfire, for example, 75% and 50% of “opportunities sourced” and “deals done” are data-driven, respectively. Is attribution for deals won similar? We’ll see.
Don’t Mirror the Past Into the Future
I share that for the screening component of the deal flow funnel, there are deterministic and statistical/ML-based approaches. While deterministic scoring contains biases and is based on a limited sample size, statistical approaches are more comprehensive but by definition just mirror the past into the future, as described in my article here.
Mike adds that one of the things that's cool about ML is that you have more tools available to quantitatively reason about the things that are influencing your decision-making. Different from human decision-making, data-driven approaches, and ML allow us to mathematically identify biases and model them accordingly.
Danish feels that biases can be sometimes even helpful as long as they can be split into promoters and detractors for creating alpha, referring to awareness. Philipp concludes on this point that it’s not all about the data but how we look at the data. Again, this supports the point made earlier on the “taste” of different firms.

Small vs Big Funds, Make vs Buy
One of the 60+ questions from the audience popped up about make vs buy and how small firms that cannot afford internal engineering teams might approach the DDVC revolution. I replied with the barbell approach that I described in my “10 Predictions About the Future of VC” article before.
In short, I feel that if you’re a small boutique firm doing a handful of investments per year, you don’t need any DDVC tool but should rather double down on your network and nurture it as much as possible to see and win high-quality deals. On the contrary, growing firms that need to deploy more capital and do tens of deals per year will struggle to rely purely on their network. They need data-driven approaches and technology to stay competitive and find the best deals in a wider pond.
On buy vs build, Mike has a clear perspective that if you have a truly differentiated tech stack, you would never sell it but leverage it to deploy as much capital as possible and create alpha. Said differently, if it’s a differentiation and you can build it, then build it.
I added that it mainly depends on which part of the value chain we speak about. As said earlier, data might eventually become a commodity. Buying it externally, if available and meeting your requirements, seems like the logical conclusion.
The signal as a result of processed data, however, is something truly unique. If you can afford to run the feature engineering and scoring algorithms internally, I always would keep it proprietary. Why would you buy a signal that is available to everyone else in the market? Per definition, if it’s available to all investors at the same point in time, you won’t be able to create alpha and it will only be useful for the investor being able to strike a deal. I feel that buy vs build depends a lot on your firm’s situation and the budget available.
Conclusion
The best time to plant a tree was 20 years ago. The second best time is today. Now is the best time to start shaping the Future of VC. If you’re interested in joining future formats like this one, sign up here.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues, and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎