

"If Everyone Has the Same Data, How Can You Even Differentiate?" Here is how.
"If Everyone Has the Same Data, How Can You Even Differentiate?" Here is how.
DDVC #46: Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts, and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 11,860, +310 since last week
Brought to you by VESTBERRY - A tool designed specifically for data-driven VCs

Request your FREE demo account to explore the potential of establishing live data links from over 300 diverse data sources, apps, and platforms, paving the way for distinctive VC insights.
Information is the currency of venture capital investors. Being the first to know about a new stealth founder or a traction inflection point of a growing startup on your watchlist can be the headstart you need to get into their next funding round.
Historically, there was only one way to get such information: Deep-rooted networks and quid pro quo. While from the outside it seems that the socializing “vine and dine” culture of VC is a nice side product of the job, it’s actually an important process component to procure sensitive information in a world where companies and their investors are private by nature.
However, once the word is on the street, be sure you’re not the only one chasing this hot company: Time is of the essence. Thankfully, data-driven approaches allow us to gain a significantly more scalable edge in this information-centric industry. But how can it actually create an edge if everyone accesses the same information? Read on.
What’s the difference between information and data?
Let’s start with some important terminology. The terms "data" and "information" are often used interchangeably, but they have distinct meanings. Data refers to individual, raw facts or observations, while information represents the processed, structured, and interpreted collection of those facts. To draw an analogy, if information is the final puzzle, then data represents the individual pieces.

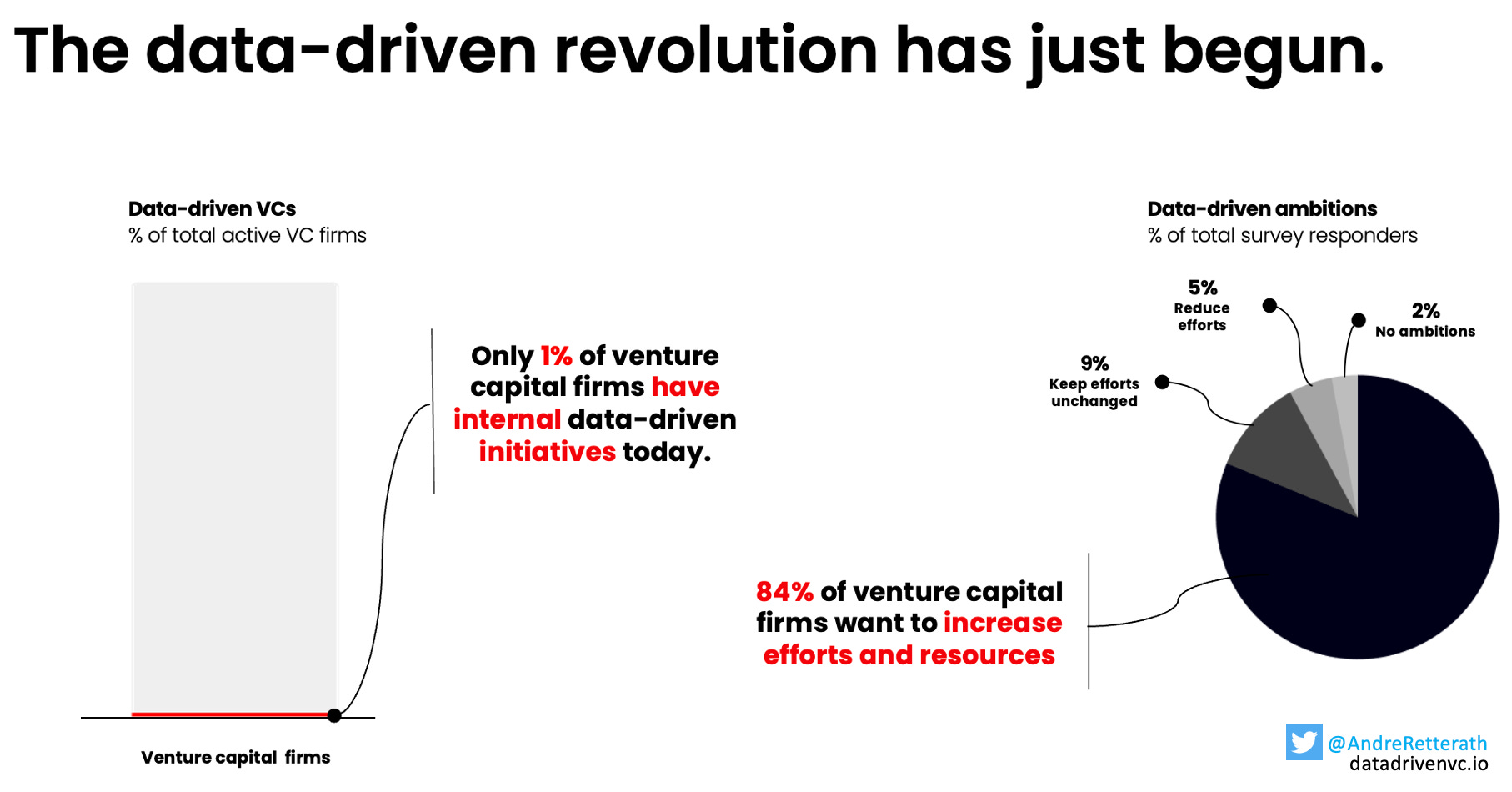
In a world where information is the currency and time is of the essence, proprietary access to relevant data becomes an unfair advantage. It allows you to gradually assemble the puzzle and draw conclusions at any point, even before you see the full picture. There is no reason to wait for information from your network if you collect the underlying data and put one and one together. Yet, the majority of VC firms still heavily rely on their human networks and are only about to start their data-driven initiatives.
Mission-critical information for VCs
In line with the most critical parts of the VC value chain (see detailed post here), investors are mostly interested in two types of information:
Sourcing: Who is about to start a new company? The goal is to achieve comprehensive deal coverage.
Screening: Which company to focus on? The goal is to track the right companies and catch relevant inflection points to re-engage.
Most investor meetings revolve around these deal origination-centered questions. To overcome the natural limitations of human networks and scale information procurement, you need to put in more effort and look at the pieces of the puzzle instead of waiting for the final picture to be presented. A competitive edge doesn’t come easy, so let’s get our hands dirty.
The data-equivalents to the above-mentioned information are:
Identification data for comprehensive sourcing coverage, i.e. where/how can we first identify a digital footprint of a new company?
Enrichment data for effective screening filters, i.e. where/how can we first anticipate an inflection point for a specific company?
I wrote extensively about different approaches for the data collection on 1. and 2. here in “How to not miss an investment opportunity anymore”. As a reaction to the presented approach, I oftentimes get the question:
“If everyone has the same data, how can you even differentiate?”
Let me answer it with another analogy. Large language models (LLMs) are algorithms that got pre-trained based on publicly/commercially available data. Hereof, all users get more or less the same results. While this is sufficient as long as none of your competitors uses the same model, increased adoption will require fine-tuning with proprietary data to maintain an edge and get better results than others.
Equally, a data-driven VC (DDVC) tech stack is mostly based on publicly/commercially available data such as public registers, LinkedIn, ProductHunt, Crunchbase, Dealroom, Synpatic, Harmonic, Gravity, and many others. It’s extremely powerful in a world where few VCs have adopted a DDVC approach. Yet, the competitive edge will diminish as more VCs start leveraging the same sources. If you’d stop here, I’d fully agree that DDVC differentiation would be limited.
A Data-driven VC (DDVC) tech stack is like a large language model (LLM), it requires fine-tuning with proprietary data to achieve long-term differentiation.
Combine publicly available data with unique internal data
Therefore, it’s crucial to move ahead as quickly as possible: Taking your existing internal data such as previous investment memorandums, pitch decks, data rooms, founder assessments, metric benchmarks, decision outcomes, email communication, call notes, board documents, and a lot more pieces of the puzzle that are only available to you, will allow you to “fine-tune” your DDVC stack and get ahead of your competitors.
While proprietary data matters less for sourcing/identification, it’s crucial for screening/enrichment as the “fine-tuned” models can perform more effective deal qualification.

Conclusion
Even if you haven’t started your DDVC journey yet, think ahead and store your proprietary data in a structured way wherever you can. Always ask yourself: “How can I capture data on every part of the decision-making process?” It will be the key ingredient in the future to maintain a competitive edge as a VC.
For example, in 2018 we introduced an assessment survey with multiple dimensions to be filled in after every investment committee at Earlybird. Until today, we have collected close to a thousand individual responses from our team members on hundreds of individual companies that we invited to our IC. Another example is that following the introduction of our new CRM system Affinity in 2018, we added a required label “founder assessment” to be filled in by our team members after every initial founder meeting. Until today, we have collected tens of thousands of subjective founder assessments.
Based on our 26 years of (data) history at Earlybird, these proprietary pieces of the puzzle allow us to identify internal biases, fine-tune our deal recommendation engine, improve our ranking algorithms, and a lot more to see the full picture earlier than others do. It’s a flywheel where our platform EagleEye provides value to the investment team, who in turn enjoy interacting with it and allow the system to capture further data to improve the underlying models.
In terms of DDVC, this proprietary data is the actual gold. This is the long-term value, just like for LLM providers who are on the hunt for new data partnerships and seek to find ways for their customers to fine-tune models with proprietary, oftentimes sensitive data.
To sum it up, leveraging publicly available data for sourcing/identification and screening/enrichment today, in a world where only 1% of VCs have DDVC initiatives, creates a strong edge. Yet, with increasing adoption over the years to come, this edge will diminish as more VCs start relying on similar external data. Therefore, I expect collecting and merging proprietary internal data into the equation will be the eventual unfair advantage on the DDVC side of things. Fine-tuning screening models with proprietary data will more effectively allow VCs to cut through the noise and get in front of the right entrepreneurs ahead of everyone else.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues, and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎