

Data-driven VC #1: Why VC is broken and where to start fixing it
Data-driven VC #1: Why VC is broken and where to start fixing it
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
First off, I’d like to thank all of you for your crazy support and interest in this project. I’m still blown away that more than 830 of you subscribed to this newsletter within 24 hours after the initial launch on Monday. BIG THANK YOU! And now let’s jump right in..
The status quo in VC
I always appreciate great structure, so let’s start with a simple framework to understand the status quo of our industry: the VC value chain. On the highest level, GPs must first collect money from LPs, then invest and help their portfolio grow before ultimately divesting and returning the initial commitment plus returns to their LPs. Simple and straightforward.
But where do VCs create actual value? Well, for this question we can easily cut the first (money in from LPs) and the latter part (money out to LPs) to remain with the core, the so-called “investment/decision-making process”. Yes, we do create value for our LPs beyond money too, but this is secondary as the primary job of a financially oriented VC is to deliver returns. Outstanding returns. To better understand the levers of this part, let’s focus on the core value creation. Below you can find a table summarizing major frameworks depicting the different stages of the investment/decision-making process.
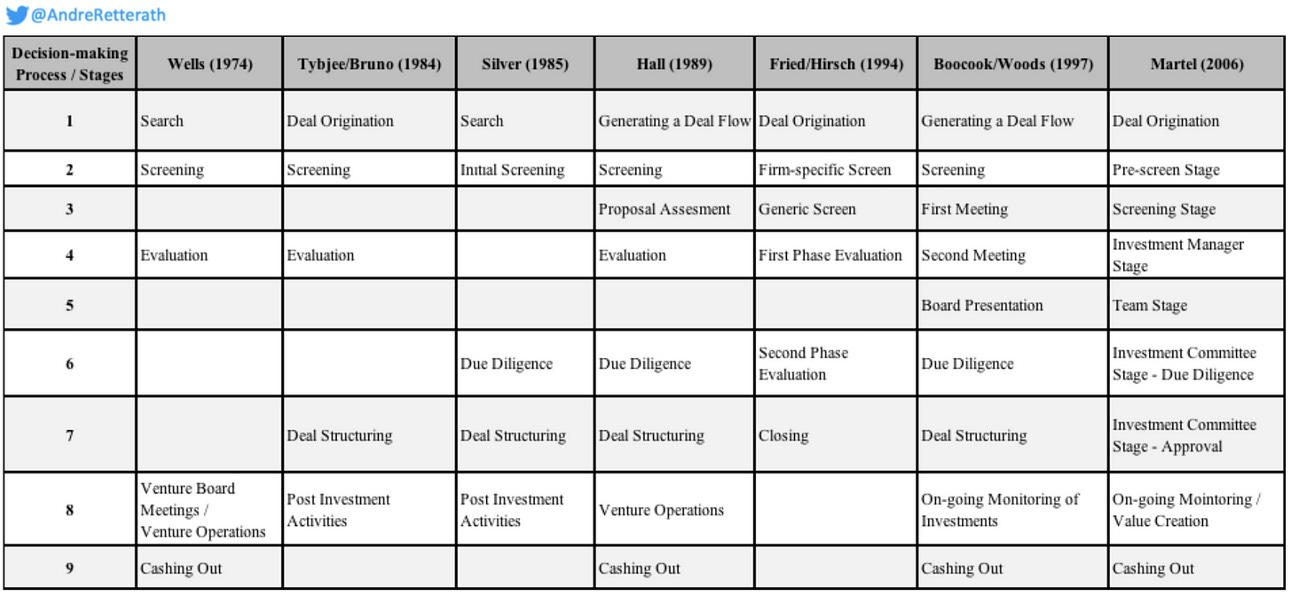
For simplification, I distilled the major steps into a streamlined 7-staged process described in the figure below. Hereof, I highlighted the most obvious shortcomings and bottlenecks in the respective stages. Certainly, this is far from being exhaustive, but sufficient for our purpose.
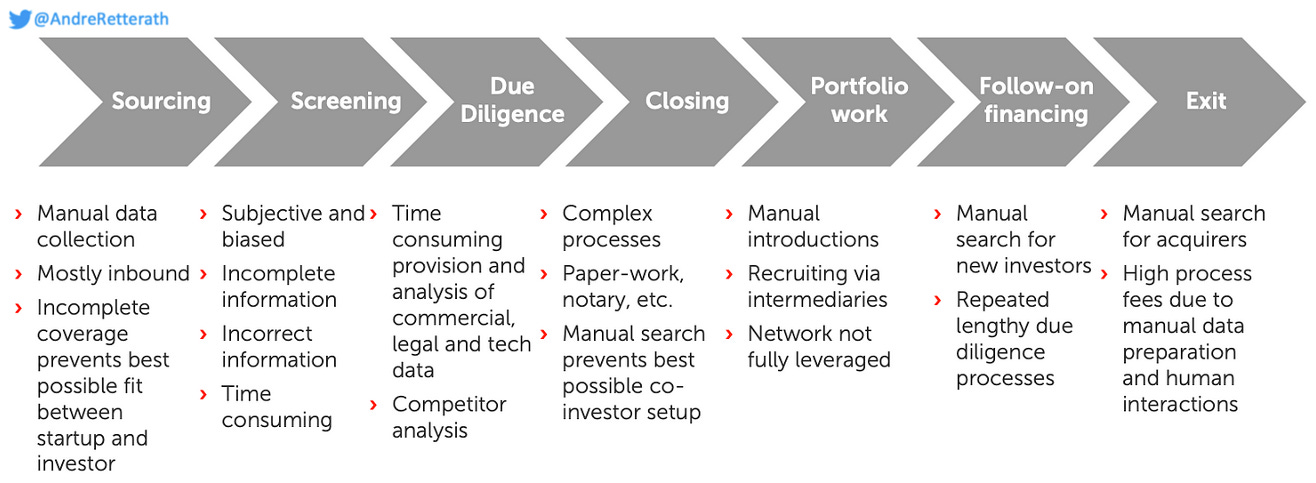
In a nutshell, the VC investment/decision-making process is manual, inefficient, non-inclusive, subjective and biased which leads not only to a huge waste of resources but more importantly to sub-optimal outcomes and missed opportunities.
But wait.. hasn’t it actually worked OK until now?
Well, yes. But competition among VCs has exploded in recent years and some early movers among them have started to innovate 👋🏻 To understand this trend in a bit more detail, I’d like to lean on the Supply and Demand Law and adapt it to the VC world: supply (startups) and demand (capital to be invested).
While several sources provide evidence that the number of startups has always been — independent of economic conditions — approximately constant (source), the capital to be deployed has exploded, not only due to cheap money politics but also due to an increasing attractiveness and better accessibility of VC as an asset class. For example, the total value of VC funds raised grew by 5.2x from $3.5bn in 2009 to $18.2bn in 2021 (source) which can be attributed to more funds raised but also to larger funds raised (source). As a result, an increasing number of VC firms needed to invest an increasing amount of capital into a limited number of assets. Obviously, this imbalance led to an increase in startup valuations* but more interestingly to VCs becoming more creative in their investment process.
*Excursion: While valuations exploded in the months and years before Q1 2022, recent reports show a contraction that began in Q2 2022 and is expected to last at least until 2023. Although complex to prove, I’m convinced that this contraction driven by macroeconomic reasons is only temporary and that VC as an asset will continue to flourish on a global level, read my perspective on the European ecosystem here.
So yes, the traditional (manual, inefficient, subjective, non-inclusive..) VC model worked OK. However, not because it was flawless, but rather because of the lack of competition among VCs. With the above-described rationale, it’s clear that times have changed and that the increased level of competition pushes VCs to innovate.
Where to start innovating in VC?
Thankfully Morten Sorensen (2007, “How smart is smart money”) found in his study that about 2/3 of the VC value is created in the sourcing and screening stages of the investment process. Said differently, VC is a “finding and picking the winners game”, so according to him, it’s clear where to start innovating. On a more symptomatic level, Paul Gompers, Will Gornell, Steve Kaplan and Ilya Strebulaev (2020, “How do VCs make decisions”) confirm this view as they observed a shift in the sourcing distribution. While 58% of deal flow across VCs was historically inbound (meaning that founders reached out to the VCs), the authors find a strong trend towards outbound (meaning that VCs reach out to founders), stating that “these results emphasize the importance of active deal generation”.
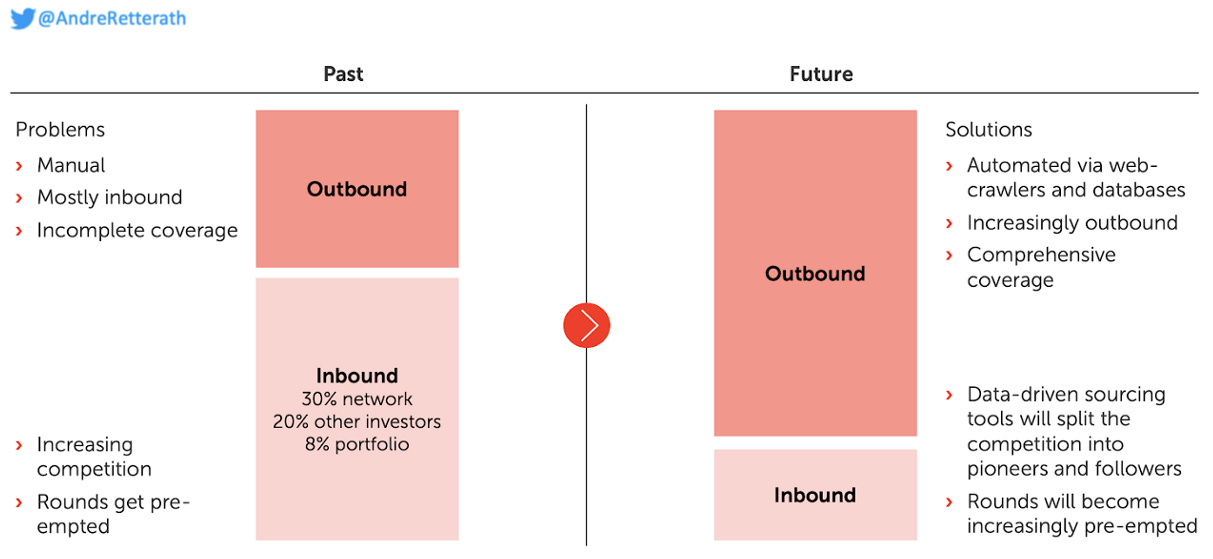
Bottom-line: Both the value-based perspective as well as the symptom-based perspective suggest that major innovation in VC has started in the sourcing and screening stages of the investment process. Accordingly, the next episodes of this newsletter will explore the full spectrum of sourcing approaches ranging from scouting programs (university ambassadors, angel programs, etc) over fund of fund investments to - for me the most relevant path - more scalable data-driven methods.
More specifically, I will dive deeper and compare commercial startup/VC databases like Crunchbase, Pitchbook, CBInsights and co, dissect alternative data sources like SimilarWeb, Data.ai/AppAnnie, Semrush or SpyFu, explain in detail why and how to crawl your own data (including the need for distributed proxy servers and the easy but expensive way out via full-stack crawling providers like PhantomBuster, Apify, TexAu or Captain Data), and explore methods to merge different datasets together on an entity/startup level.
Stay driven,
Andre
PS: Feel free to share your ideas and alternative data sources via andre@earlybird.com and I will make sure to include a review + share a list with all inputs in one of the next episodes!
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Very excited that you launched this newsletter. I came across an article about your work in the Handelsblatt a few years ago, which happened to inspire my Master‘s thesis about the impact of data driven decision support systems on VC‘s decision-making. Looking forward to reading more about your thoughts and ideas!
Great insights but as an industry outsider the abbreviations don't seem too clear from the start. Could you write out the abbreviations once? I read GP as general practitioner...(medical domain) and don't enjoy switching to the search engine myself. Makes a better reading flow as well. Cheers!