

How AI Enables One-Person Billion-Dollar Companies
How AI Enables One-Person Billion-Dollar Companies
Leverage Technology to Achieve More With Less

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Tuesday, I publish “Insights” to digest the most relevant startup research & reports, and every Thursday, I publish “Essays” that cover hands-on insights about data-driven innovation & AI in VC. Follow along to understand how startup investing becomes more data-driven, why it matters, and what it means for you.
Current subscribers: 20,880, +220 since last week
Brought to you by VESTBERRY - Portfolio Intelligence Platform for data-driven VCs

Data Engineering is no longer just a backstage player but is taking center stage in the VC space. It is about constructing and maintaining the architectures (think databases, large-scale processing systems) that allow for data availability—a cornerstone for insightful analysis and well-informed decisions.
Dive deeper into this video, where we break down the impact of data engineering on the VC industry. Turning raw data into usable outputs and insights has great use cases for deal sourcing, due diligence, or portfolio monitoring.
The Big Bang of GenAI
Yesterday, I gave a talk at the Chatbot Summit 2024 in Berlin about how AI changes the future of work. In light of the great conversations and feedback that followed my talk, I decided to turn extracts of my presentation into this episode.

In order to understand the impact of AI on the future of work, we first need to understand why we are witnessing the big bang of gen AI today, and not already years before. Keeping things simple, I split the Cambrian explosion of GenAI into three ingredients: Algorithms, Compute, and Data - “The Magic Triangle of AI”.

First AI algorithms evolved in the 1950s. Moore’s Law described the evolution of computing power in the 1960s, but it took until the 1990s to reach first breakthroughs with CPUs. Data became a thing in the early 2000s, with the “big data” and “data is the new oil” hype following thereafter.
About ten years later, about a decade ago today, we moved from sequential to parallel computing and GPUs, a significant acceleration in computing power. While the “Attention is all you need paper” introduced transformers as the breakthrough algorithms, it seemed the magic triangle had been completed, yet AI didn’t take off.
Why? Because awareness of its power had been limited to a group of privileged nerds in the bubble. The majority of our society had never heard about transformers, GPTs, and alike. Only the introduction of ChatGPT, an interface on top of GPTs, changed this end of 2022.
This interface has allowed humans to suddenly interact with LLMs through natural language instead of programming code. A milestone that will most likely be remembered as the inception of AI, even though in reality it took 70 years and advancements across all three components of the magic triangle to get there. What lasts long will eventually be good.
Cost of Experimentation Framework
During my PhD days at the Technical University of Munich, one of my colleagues researched the impact of different technologies on the “cost of experimentation”, a term to describe the resources required to start a business. A well-cited study in this domain is the “Cost of experimentation and the evolution of venture capital” paper by Ewens, Nanda, and Rhodes-Kropf (2018).
The introduction of cloud computing services by Amazon is seen by many practitioners as a defining moment that dramatically lowered the initial cost of starting Internet and web-based startups. (..) We show that subsequent to the shock, startups founded in sectors benefiting most from the introduction of AWS raised significantly smaller amounts in their first round of VC financing. (Ewens, Nanda, and Rhodes-Kropf, 2018)
I first took this framework and applied it to AI about a year ago here, predicting that similar to the introduction of the cloud, AI is about to increase productivity and thus significantly decrease the cost of experimentation. As a result, I assumed that AI would be a monumental driver for companies to achieve more with fewer resources.
Looking for real-world data to confirm the academic concept above, I came across recent Statista data, providing clear evidence for the decreasing number of employees required to generate $ 1M in revenues. The perfect efficiency metric to validate the cost of experimentation concept, as shown on the right in the slide below.

One-Person Billion-Dollar Companies
As Sam Altman recently described this trend:
“We’re going to see ten-person billion-dollar companies very soon (..) and there’s this betting pool in my group chat with these Tech-CEO friends for the first year when there’s a one-person billion-dollar company, which would’ve been unimaginable without AI”
What Does This Mean for Businesses, Employees, and the Future of Work?
Well, I see two theoretical scenarios:
Fix the input and increase the output: More economic output, higher GDP, etc., and eventually a higher concentration of value.
Fix the output and decrease the input: Reduce the work hours while achieving the same economic output. Tim Ferris was ahead of his time when he predicted the “4-hour work week” in 2007.
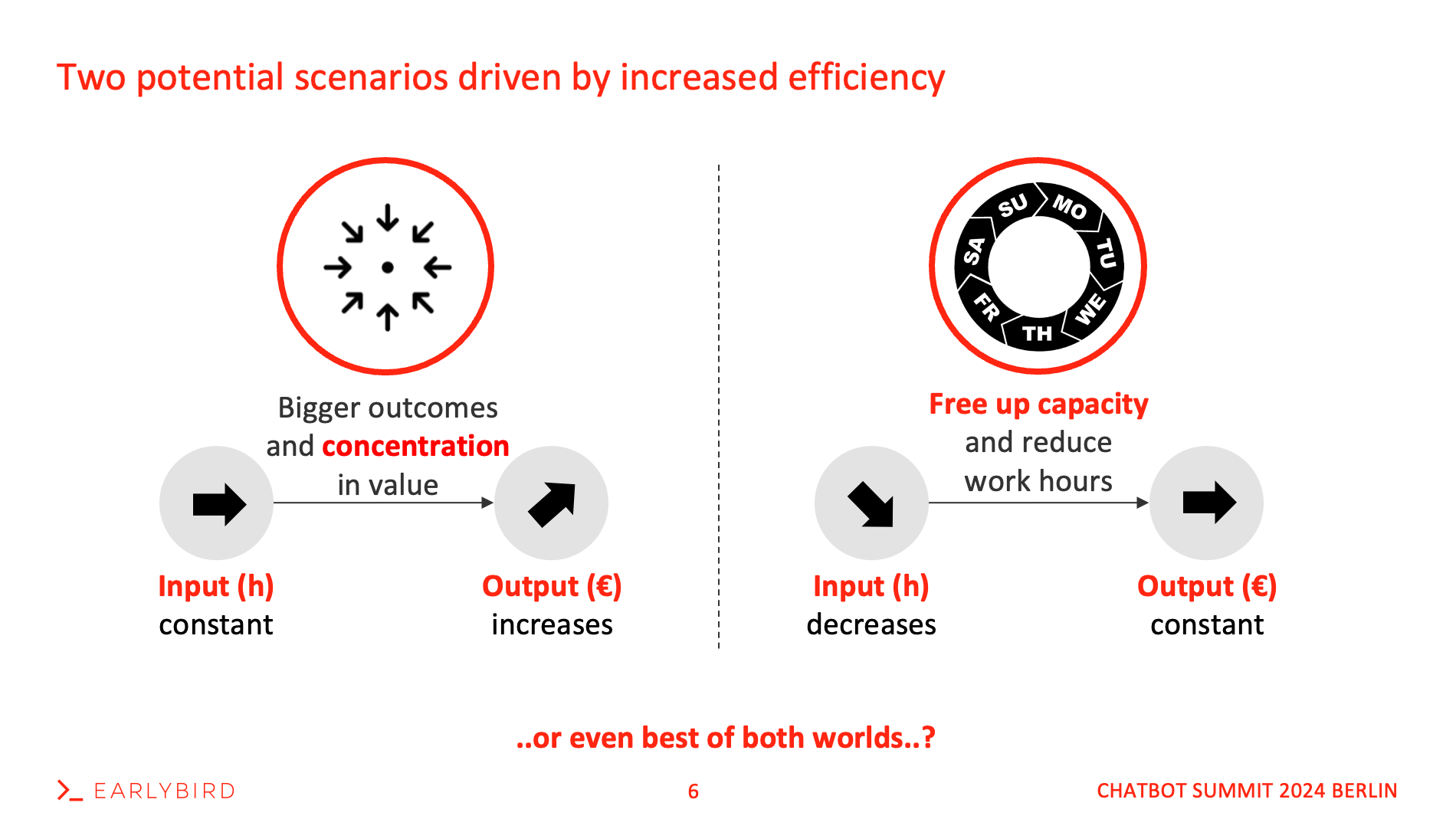
Less than two decades later, this back-then idealistic picture of a 4-hour work week might soon become a reality.. at least we’re trending towards it.. Democrats recently cited AI gains and automation in a Senate bill calling for a 32-hour workweek. The first serious attempt to reduce the 40-hour workweek we’ve known for more than a century.


Conclusion and Why It Matters
On a more macro level, AI reduces the cost of experimentation and allows individuals as much as companies to achieve more with less. Starting a company and finding product-market fit can be achieved with fewer resources and the help of copilots or AI-powered products, and in most cases does not require a team of deep experts anymore.
Long-term, I expect more company formations but overall fewer yet significantly bigger outcomes. The longtail will become even longer with an increased concentration of value in fewer players at the top end.
Ten years ago, nobody would’ve believed we’d ever see trillion-dollar companies. Looking at the Magnificent Seven today, we see six of them with a market cap of more than a trillion dollars, i.e. Microsoft ($ 3TN), Apple ($ 2.8TN), Alphabet ($ 1.8TN), Amazon ($ 1.7TN), NVIDIA ($ 1.7TN), and META ($ 1.6TN). All of them being tech companies and are at the forefront of developing or leveraging modern technologies like AI.
It’s obvious that if we continue on this path, which seems inevitable if we believe in the cost of experimentation framework above, we need to think about the broader implications for society and discuss universal basic income, AI tax, and other instruments sooner than later.
On a more micro level, I can only repeat that if you work in front of a screen and don’t use copilots or AI-assisted products today, you won’t be competitive anymore tomorrow. Period.
Stay driven,
Andre
Thank you for reading this episode. If you enjoyed it, leave a like or comment, and share it with your friends. If you don’t like it, you can always update your preferences to receive just the regular Thursday “Essays”, just the Tuesday “Insights”, or both. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Very interesting article and 100% agree on the direction. A couple of points and I am curious for your perspective: (1) we know that LLMs, in the current configuration, are exceptional at gathering and surmising information (nb: which is problematic on its own), and there is the "degradation of quality" issue that often leads to "hallucinations". What's your perspective on how this is likely to have an influence in high-stakes decision-making within business environments (even political/policy-making) and what are your thoughts on how this will be overcome? (2) What are your thoughts on building reasoning capabilities and how could you see this emerging in which precision-level insights? We know that powerful knowledge bases exist (including emerging Graph of Thoughts etc) that point towards potential solutions, but this have a scalability problem yet offer very precise and specific insights when combined with LLMs. How do you see these forms of technology working together (or others)?