

Data-driven VC #8: 3 steps to convince the data-skeptics/dinosaurs
Data-driven VC #8: 3 steps to convince the data-skeptics/dinosaurs
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 2,400, +313 since last week
Tl;dr
Convince the “VC is more art than science and impossible to automate”-skeptics with a simple but powerful 3-step approach
#1 “Inception”: Defeat initial skepticism with an objective benchmarking study; my “Human versus computer benchmarking study” shows that a basic XGBoost classification model predicts startup success at least as well as the best VC, 25% relatively better than the median VC and 29% relatively better than the average VC in our sample of 111 investors
#2 “Acceleration”: Deliver short-term ROI by creating strategic value for (new) LPs which then invest (more) money into your fund; the additional management fee justifies investments into a data platform and an engineering team
#3 “Final”: Deliver long-term ROI by a) identifying outlier opportunities that deliver superior returns for LPs and b) gaining a competitive edge towards founders that provides preferred access to the outlier opportunities; I show different ways of how to measure these dimensions
VC as an industry started in the 1940s and has seen little change ever since. The only visible progress was the move from pen and paper to computers, Excel and Powerpoint, as well as the recent shift from in-person meetings to more virtual meetings (at least for intro meetings; less for deep dive due diligence and team assessments) driven by COVID. That’s it. No other change, innovation or whatsoever. Isn’t it confusing that those who back the most disruptive entrepreneurs themselves still work like 80 years ago?

VCs historically refused to innovate
Trying to understand the root cause of innovation blockers in VC, I spoke to 150+ senior investors globally in the past 5 years. The spectrum of answers is wide, however, one single argument is front and center: “VC is more art than science. It is a human business that cannot be automated”. I agree but at the same time disagree. Yes, some parts of the value creation are more art than science (such as the final investment decision, looking each other in the eyes and deciding to partner together), but still, there are several components that are more science than art and can easily be automated (such as the data collection, identification, enrichment or screening).
I’ve walked you through my thinking on data collection, entity matching and feature engineering in previous episodes. There is really no need to explain why computers can do better than humans in these tasks. On the screening, however, skeptics are hard to convince and this is really where the above-mentioned statement is rooted. I framed this blocker as the “Automation-Control Trade-off” in the previous episode.

To solve this initial friction (=”Automation-Control Trade-off”) and justify subsequent investments into a holistic data-driven platform that is developed and maintained by an expert engineering team, I established a 3-staged strategy to convince the data-skeptics/dinosaurs.
Step#1 “Inception”: Solving the “Automation-Control Trade-off”
Considering the asymmetric cost matrix in screening (where false negatives are more costly than false positives; NOTE: it’s different for the final decision and we only focus on the screening here), VCs simply do not trust algorithms when it comes to the most critical part of their investment process.
To help resolve this trade-off and to allow the VC investment process to scale, I trained several ML-based screening algorithms, selected the best-performing one based on recall rate (inverse of false negative rate) and transparently compared its screening performance to the performance of human investment professionals. Why? Well, it’s hard to argue against data 🤓
Summary of “Human versus computer: Who’s the better startup investor?” benchmarking study
Purpose: Compare startup investment screening performance between ML-based algorithms and human investors
Metrics: Accuracy (AC) and recall (RE); the higher AC and RE, the better
Data sources: Based on our database benchmarking study (must read when working with startup data), I selected Crunchbase as the basis and matched it with Pitchbook and LinkedIn information
Test sample: 10 European software startups with anonymized input info right after they raised their Seed round in 2015/2016; 5 successful and 5 unsuccessful as of 2020
VC respondents: 111 investors
ML training sample: 77,279 European software startups, founded after 01.01.2010, run by 118,231 verified founders
ML algorithms (see Table 4 for comparison): decision trees (DT), random forests (RFs), gradient-boosted trees (also known as “XGBoost” (XG)), naive Bayes (NB), deep learning (DL) models, generalized linear (GL) models and logistic regressions (LRs)
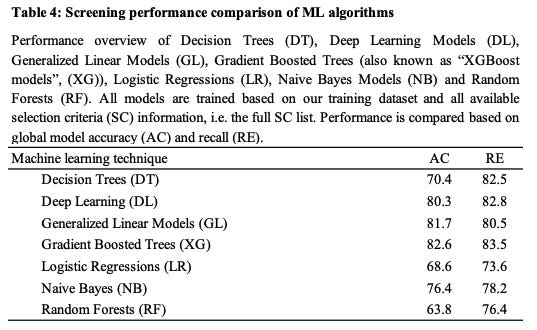
After training and selecting the XGBoost model as the best-performing one for our use case, I provided equal information in the form of 10 company one-pagers via an online survey and requested that respondents select the five most promising companies for further evaluation (=screening process; not final investment decision). The same input information was provided to the XGBoost algorithm in order to do the same. Neither party had seen nor analyzed the information contained in the test dataset before.
Benchmarking results (see full study here, including patterns of VCs who perform best in screening)
I find that a basic XGBoost classification algorithm that was solely trained on Crunchbase, Pitchbook and LinkedIn data performs at least as well as the best VC in our sample. Moreover, it performs relatively 25% better than the median VC and 29% better than the average VC in screening and selecting European early-stage software companies.

See here for another benchmarking study called “Do Algorithms Make Better — and Fairer — Investments Than Angel Investors?” With these simple but powerful results at hand, I personally was able to get initial buy-in and started developing an MVP of our data-driven sourcing AND SCREENING (!) platform. Quickly, I got to the level where I needed more resources and deeper expertise (specifically across backend, frontend and data engineering) across the stack. The logical next step would be to hire engineering experts.. but I can ensure you, skeptics won’t miss a chance to challenge your plans and question any investment. Let’s shift gears!
Step#2 “Acceleration”: Short-term ROI, the strategic LP argument
Assuming we defeated the initial skepticism and have successfully developed an MVP, the next logical step is to double down and hire engineering experts (more on how to build an Engineering team within a VC in future episodes) to transform the MVP into a fully-fledged software product. Going forward, we need resources. Significant resources. In VC speak: Bootstrapping is over, our engineering team needs funding 🚀
Some background for all non-VCs among us: VCs finance their operations with management fees, typically about 2% of the overall fund size per year. Assuming that GPs are reluctant to carve out (significant) part of their existing budget, an easy argument is “if we gain additional management fee primarily due to our data-driven initiatives, it justifies an initial investment into a fully-fledged platform and team”. Although initially a chicken-egg problem, one can easily overcome it by presenting an MVP of the platform and communicating clear expectations for the future.
Yes, LPs expect primarily financial returns, that’s right. However, there is a broad spectrum of LPs who are interested in more than just financial returns, namely market insights and regular opportunities in their areas of interest. Said differently, strategic interest. This is specifically true for LPs that leverage VC fund investments as an extended strategy for corporate business development, M&A and innovation.
A simple example: If you convince an LP to invest € 5m into your fund mainly due to proprietary insights delivered by your data-driven platform (such as monthly deal-flow extracts, specific market insights/trends or opportunities to establish new business partnerships with startups or even co-invest alongside yourself), this delivers € 1m overall management fee. Now assuming that this LP continues to back future vintages, you can concentrate the €1m on the initial investment period of 2-4 years as new funds will be layered on top. In this example, we could justify € 250-500k (=€ 1m divided by 4y and 2y, respectively) p.a. investment into our new platform. Add one or two more and you’re good to go.
Step#3 “Final”: Long-term ROI, impact on daily business and performance
Finally, we overcame the “Automation-Control Trade-off” and justified an upfront investment to start professionalizing our data-driven efforts with a secondary line of argument, i.e. LPs will benefit strategically which in turn brings in the needed management fee. Well done… but I can ensure you, again, it won’t take too long until skeptics will question the actual impact on your investment business and ultimate returns.

Impact on daily business: As described in the first episode, the VC value chain is broken all across and while we start fixing it in the sourcing and screening parts, we won’t stop here but continue with due diligence, co-investor matching and post-investment portfolio value creation (PVC). Automatically collecting data, creating a single source of truth and auto-generating competitive landscapes removes the need to manually search for information and structure it accordingly. In short, it improves efficiency and, as a result, human investors can evaluate more opportunities at greater depth. This can be easily measured when tracking “time spend on tasks” for the investment team.
Beyond the sourcing and screening stages, PVC becomes highly relevant for innovation as it shapes the perceived value by founders which in turn determines access to the most promising opportunities. To be explicit, it’s not enough to identify and highlight the most promising opportunities, you also need to get access to them and superior PVC is key here. One PVC example is a data-driven recruiting platform that removes the broader need for external search firms but gives power to the founders and matches them with the right candidates. Another PVC example is the collection and structured presentation of market insights to the founders. One other… well, you get the point.
ROI for PVC initiatives can easily be measured via founder surveys that include net promoter scores (NPS) across dimensions and explicitly ask for the perceived value of such data-driven solutions and whether they impact a founder’s overall perception.
Impact on performance: Similar to the impact on the daily business, we need to distinguish our measures across stages in the value chain. For example, for the sourcing and screening parts, we can measure how many startups a fund ended up investing in per year and then split into human-sourced and ML-sourced opportunities. Moreover, we can attach more directly related performance indicators to this balance and calculate performance on ML-sourced opportunities versus human-sourced opportunities, like TVPI and DPI.
To boil it down, everyone understands that if you source one uni- or decacorn through a data-driven platform, whatever costs from the past to the future will be justified by the carry and reputation gained 💸 While this will only become visible in a few years from now, the above-described 3-staged strategy should help to turn the skeptics into supporters and start building.
This is it for today. I hope this episode will help you to convince the skeptics (in your team and beyond) as much as it helped me. Next up, I’ll dive into promoters and detractors among screening criteria and explore how an augmented approach can look in practice.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎