

Data-driven VC #7: How to automate startup screening?
Data-driven VC #7: How to automate startup screening?
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 2,087, +181 since last week

We’ve crossed the 2k subscriber mark within less than two months, thank you all! Today we’ll explore different ways of cutting through the noise and see how modern VCs find the needle in the haystack. But let’s start with a more fundamental question:
What makes a VC successful?
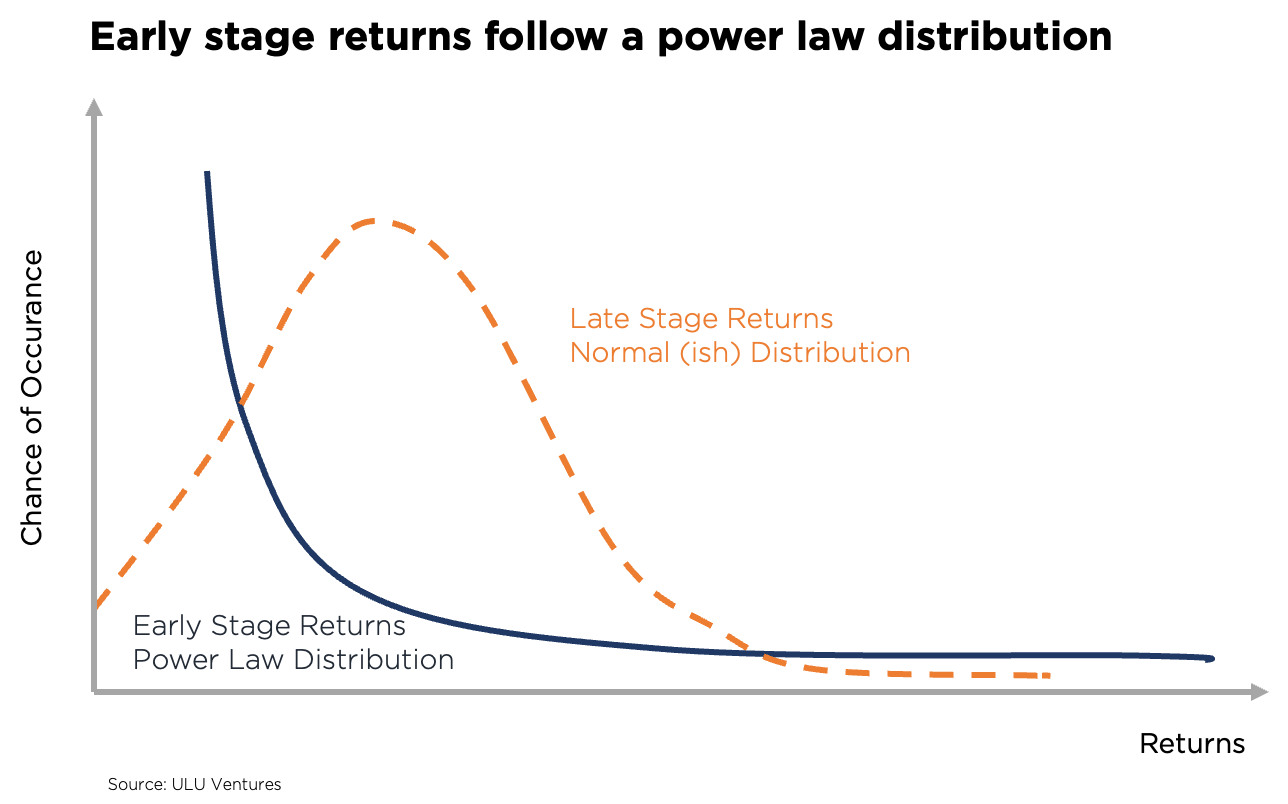
“Beauty is in the eye of the beholder” also holds true for “VC success”. Although we have been observing a shift from a pure financial return perspective to a more holistic ESG-centered one, the majority of GPs still operate with return on investment (ROI) top of their minds. On a portfolio level, early-stage VC returns are distributed based on a Power-law, whereas later-stage and private equity (PE) returns follow a normal distribution. In line with the most well-known Power-law distribution, the Pareto Principle (or “80-20-rule”), early-stage VC returns are driven by a high alpha coefficient that leads to oftentimes only 10% or less of the portfolio delivering 90%+ of the returns.
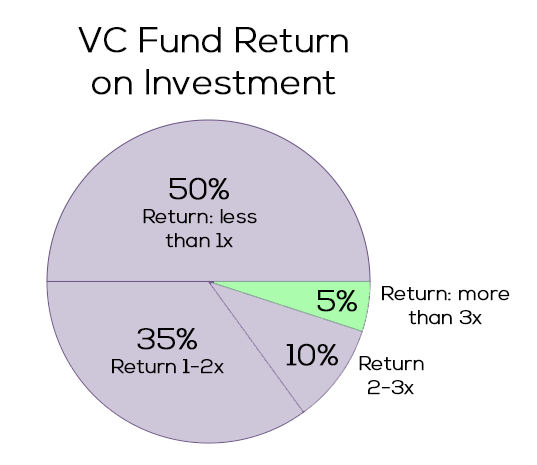
Consequently, a well-performing early-stage VC fund with a portfolio of 25-35 startups depends on one or two outlier IPOs or trade sales and is comparably insensitive to write-offs. Said differently, early-stage VCs are upside-oriented #optimistbynature, whereas growth VCs and PEs rather try to limit their downside. In turn, every VC investment needs to have the potential to become one of the few outliers. I shared my thoughts and a rule of thumb on how big your startup needs to become to be a VC investment case here.
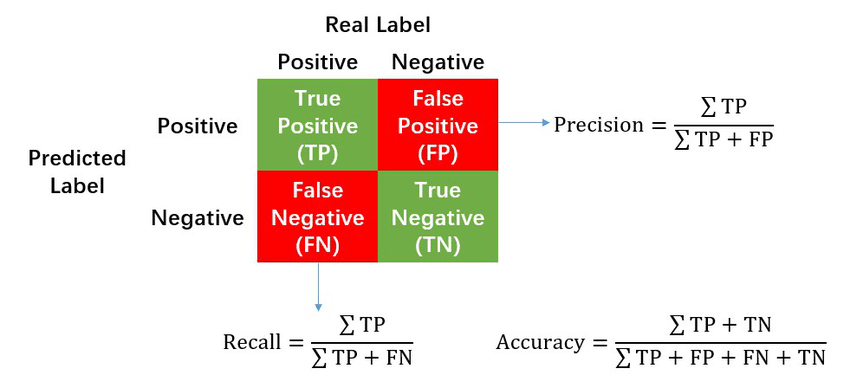
While early-stage VCs can afford to write off a significant portion of their portfolio, they cannot afford to miss an outlier. Translated into data speech: VCs face an asymmetric cost matrix where false positives (FP=decide to invest but need to write it off later) are OK/less costly as they can lose their money only once, but where false negatives (FN=decide to not invest but turns out to be a multi-billion dollar company later) are NOT OK/more costly as they miss an opportunity to multiply their money several times.
Obviously, VCs could decrease FN by investing in every company but in reality, they face natural limitations such as a) how many companies a human VC can look into more detail for screening and b) how many companies a VC can invest in given a fixed fund size, clear split of initial versus follow-on allocation and approximate target with respect to the number of companies in mind. Therefore, a successful VC needs to improve recall (=reduce false negatives) with a fixed number of investments as a limitation.
Cutting through the noise
How can VCs improve recall while being sensitive to capital constraints? Having spoken to more than 150+ VC firms about their screening processes (partially throughout the course of my PhD research, partially thereafter; detailed overview in my paper here pg11-14), I identified two important screening dimensions and four major groups of screening approaches.
The two most important screening dimensions are:
Macro screening, meaning how VCs balance different screening criteria (such as team, problem/market (size, growth, timing pull/push, fragmentation), solution/product (USP, IP, etc), business model, go-to-market motion, traction (product, financial), competitive landscape, defensibility, cap table, round structure etc) relatively against each other. For example, team matters more than market size. Overall think of the macro level as an equation like success score = a*team score + b*market score + … + n*x-score; whereas a to n are the weights of the respective screening criteria.
Micro screening, meaning how VCs evaluate individual screening criteria like “a CS undergrad and subsequent Stanford MBA with 2 years BizDev experience at a scale-up and two complementary technical founders is a great team indicator whereas a uni drop-out who disappeared from the surface and suddenly came back as single founder with a biz idea might be a bad team signal”. The example is bad, I know, but you get the point ;)
The four major groups of screening approaches are:
Manual selection through investment team: Status quo, most VCs are here. They rely on a limited sample size of success cases within their own spectrum of experiences to balance selection criteria (macro) and evaluate them (micro). All manual, no clear playbook. Different deterministic macro balancing (a to n) and micro evaluation for each team member, lead to high variability in outcomes.
Pro: high level of control & trust
Con: manual, inefficient, non-inclusive, subjective and biased for every individual team member, huge variety across the team
Manual selection through scorecards: Some VCs note down their macro criteria balance (“criteria X is more important than criteria Y”) and their micro criteria evaluation playbook (“graduate from uni O is great, but uni P is not so great”) to standardize their screening process and train more junior investment team members. See a public example of such an equation here on P9’s “VC compatibility score”. Deterministic macro balancing (a to n) and micro evaluation, but standardized across the team.
Pro: high level of control & trust, standardized across the team
Con: manual, inefficient, subjective on a team level, potentially the least inclusive approach as we need to overlap all biases of decision-makers in the fund (that are again based on very limited sample size) to end up with a tiny intersection of positive micro criteria (what is good or bad)
Automated selection through scorecards: Very similar to the previous approach, but the balancing on the macro level (a to n) as well as the evaluation on the micro level is automated via algorithms. For example, we can deterministically define that a (team weight) is 0.4, whereas b (market weight) is 0.2, and hereby consider the team as two times more important than the market. On a micro evaluation level, we can define simple dictionaries with keywords to calculate a score. For example, we can define 0 = “drop out” or “no degree”; 1 = “whatever name of a mid-tier uni” or “another name of a mid-tier uni”; 2 = “name of a top-tier uni” or “TU Munich” ;) to then calculate the team score.
Pro: high level of control & trust, standardized across the team, semi-automated, efficient
Con: subjective on a team level, potentially the least inclusive approach as we need to overlap all biases of decision-makers in the fund (that are again based on very limited sample size) to end up with a tiny intersection of positive micro criteria (what is good or bad)
Automated selection through machine learning: The most innovative and fully automated approach. We train ML models based on historic data to identify patterns that predict success in the future. While the underlying sample size is comprehensive and the model learns all available patterns, it mirrors the past into the future and only in retrospect adapts to changing dynamics.
Pro: fully automated, efficient, objective, standardized across the team, potentially the most inclusive option as it relies on a comprehensive sample size
Con: low level of control & trust, mirrors the past into the future (=only reactive)

After all, the automated ML approach seems like the most desirable solution but - for now - comes with two big blockers: the lack of trust and the fact that it mirrors the past into the future (=only reactive). While I will dedicate the next episode to how we can overcome both hurdles, I will describe the automated ML approach itself in a bit more detail below.
Training a startup screening model (detailed explanation in my paper here pg29-ff)
Input: First off, I assume that we finished the data cleaning, entity matching and feature engineering as described in episode#5 and episode#6. So let’s assume input features can now be comprehensively collected and stored in a regular cadence as a time-series dataset.
To replicate a real-world setup where we need to make a go/no-go decision based on the actual data available at the time and where the eventual success/failure will only become obvious in a few years thereafter, we need to collect input features at t1 and the output data/success label as of t2. This underpins the importance of collecting data asap and not miss postpone too much ;) The closer the period between t1 and t2 gets to the actual period of time between the initial investment period (typically years 0-3 of a VC fund) and the divesting period (typically years 7-10/11/12 of a VC fund), the better. For our purpose, approximately 5 years between t1 and t2 are optimal.
Output: Next, we need to focus on the output data, i.e. the label that we want to predict for each observation. With respect to the screening stage, we’re interested in separating the wheat from the chaff and ranking companies according to their likelihood of success. By doing this, we face a trade-off between the certainty of success and the resulting sample size.
What does that mean? If we assign a “1” for every successful company that did an IPO and “0” to all others, we will achieve high certainty but end up with a rather small sample size of a few thousand successful companies. The dataset will be highly imbalanced and the number of relevant success observations too small. If additionally, we moderate for industry and time dependencies, the sample size quickly comes down to a few tens or hundreds of successful startups and statistical significance will be out of reach.
On the opposite side of the spectrum, we could assign “1” for every company that raised a follow-on financing round and “0” to all others. In this example, we would end up with low certainty of success but a significant sample size of a few hundred thousand of startups. Even if we moderate by industry, technology and time dependency in parallel, we will end up with a sufficient sample size to achieve statistical significance. As a result, I suggest training several models based on different certainty/sample size ratios.
Model benchmarking: Once we’ve collected the input data as of t1 and defined different output labels as of t2, we can train a variety of ML models. Lastly, we need to compare their performance with a specific focus on recall. You can find an exemplary benchmarking from my “Human versus Computer” paper below.
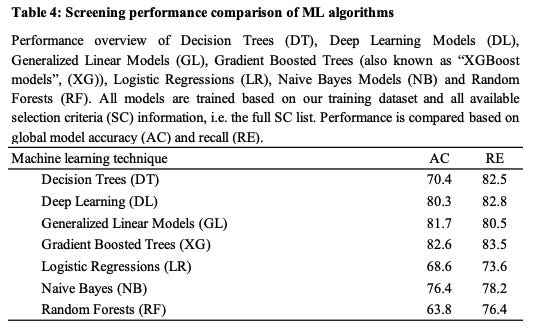
Based on the very limited Crunchbase dataset in my study, the Gradient Boosted Trees / XGBoost model delivers the best results on recall and accuracy. Important side note: I don’t think that the ML technique/model itself matters too much. As said before, feature engineering and data preparation are way more important.
That’s it for today. Next episode, I will share some insights on feature importance and explore different ways of quantifying the impact of a data-driven platform #ROI. Moreover, I will describe how I overcame skepticism and a lack of trust with respect to ML-based approaches.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Wow. Love your very technical posts.
This is an amazing resource, thank you for this substack!