

Data-driven VC #5: How to create a single source of truth for startups?
Data-driven VC #5: How to create a single source of truth for startups?
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 1,646, +203 since last week
Welcome to so many new readers this week! To bring everyone up to speed, I’d like to start with a quick run-through of the previous episodes and their major takeaways.
In episode#1, I summarized why VC is broken and found that 2/3 of the VC value is created in the sourcing and screening stages. Said differently, VC is a “finding and picking the winners game” which consists of two different tasks: 1) comprehensive identification coverage top of funnel and 2) enough enrichment data to cut through the noise. Hereof, episode#2 explores a variety of novel human-centric sourcing approaches and why comprehensive coverage is only possible with data-driven methods. Episode#3 then compares “make versus buy” with the result that a hybrid setup is the way to go. Moreover, it contains my database benchmarking study from 2020 with the finding that Crunchbase is the best value for price. Subsequently, episode#4 describes how the foundation of Crunchbase (or any other commercial dataset) can be complemented via scraping and crawling of alternative data sources.
Assuming all previous steps have been properly implemented, we end up with comprehensive coverage and multiple datasets that altogether include every startup company in the world. At least once.. or twice.. or more.. Let the clone wars begin!

How to deal with duplicates?
Given that we collect data from multiple data sources, we face two major problems (aka “the clones” or duplicates):
Redundancy/duplicates in companies
Redundancy/duplicates in features of the respective companies
Below figure shows a simple example for 1. redundancy/duplicates in companies across three different data sources: Crunchbase (CB), LinkedIn (LI) and Companies House (CH, the UK public register). It shows some overlap between LI and CB, some between CB and CH, some between CH and LI and, the tiniest part in the middle, some between LI, CB and CH. As a result, many companies are included once (no overlap), some of them twice (overlap between two sources) and a few of them even in all three datasets (overlap of all three sources in the middle).
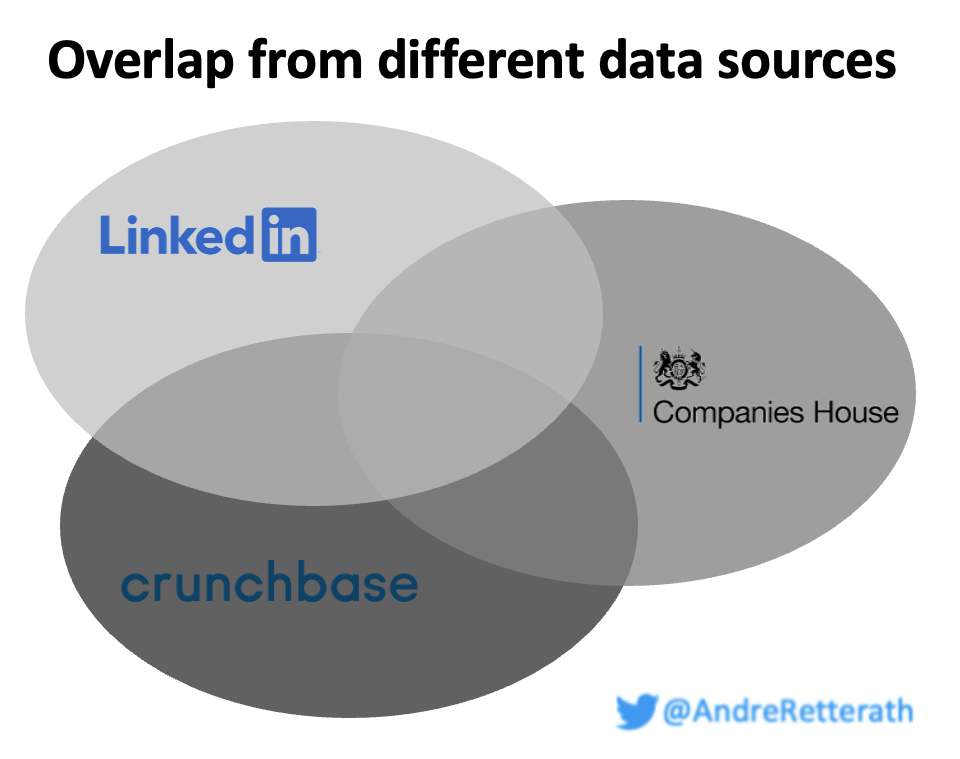
To properly present or extract value from the data, we first need to remove company redundancy and create a single source of truth. Every company needs to be included once, no more and no less.
The holy grail: Entity matching
Entity matching, entity linking, re-identification, data linkage and many more terms actually describe the same approach: Identify all record pairs across data sources that refer to the same entity. There are basically two buckets of methods: rule-based and deep learning-based ones.
Rule-based Fuzzy String Matching, also known as Approximate String Matching, is the process of finding strings that approximately match a pattern. A good example is Fuzzywuzzy, a python library that uses Levenshtein Distance to calculate the differences between sequences and patterns. It solves problems where an entity such as a person’s or a company’s name can be labeled differently on different sources.
Some code snippets below to import and execute a similarity matching of the exemplary parameters “Visionary Startup#1 Limited” and “Visionary S#1 LTD”.
from fuzzywuzzy import fuzz
from fuzzywuzzy import processfuzz.ratio("Visionary Startup#1 Limited","Visionary S#1 LTD")
#94fuzz.partial_ratio("Catherine M. Gitau","Catherine Gitau")
#100
In the following example, I’ve switched the parameter “Visionary Startup#1 Limited” to “Startup#1 Visionary Limited” to showcase the impact of the order.
fuzz.ratio(“Startup#1 Visionary Limited”,"Visionary S#1 LTD")
#52fuzz.partial_ratio(“Startup#1 Visionary Limited”,"Catherine Gitau")
#58
We see that both methods are giving out low scores, this can be rectified by using token_sort_ratio() method. This method attempts to account for similar strings that are out of order. For example, if we used the above strings again but using token_sort_ratio() we get the following.
fuzz.token_sort_ratio(“Startup#1 Visionary Limited”,"Visionary S#1 LTD")
#96
So far, so clear for the fuzzy string matching. Next, we need to ask the question “which features are likely to be included across sources and are suitable for fuzzy string matching?” The most obvious ones are “company name”, “website URL” and “headquarters/location”. Therefore, we need to establish a logic that runs a fuzzy string matching on the company names, website URLs and headquarters/locations of all companies in the dataset.
We can even add more rule-based layers such as calculating the physical distance between the zipcodes of the headquarters or creating a dictionary of keywords that can be identified in the descriptions. The occurrence/frequency of specific keywords across descriptions can then be measured and compared across companies to measure similarity. Read this paper on matching CB and patent data for further rule-based fuzzy string-matching ideas specifically for startups.
Subsequently, we need to aggregate the individual similarity scores across features into one unified similarity score per compared company sample, i.e. it’s important to score high similarity across features, not only in one or few. The unified similarity score threshold of “match” versus “no match” depends a lot on the number of data sources and included features. Therefore, I suggest playing a bit around and manually finding the optimal threshold for automated matching in your specific setup.
Neural networks and deep learning-based matching approaches are able to learn useful features from relatively unstructured input data. Central to all these methods is how text is transformed into a numerical format suitable for a neural network. This is done through embeddings, which are translations from textual units to a vector space – traditionally available in a lookup table. The textual units will usually be characters or words.
An embeddings lookup table can be seen as parameters to the network and be learned together with the rest of the network end-to-end. That way the network is able to learn good distributed character or word representations for the task at hand. The words used in a data set are often not unique to that data set, but rather just typical words from some language. Therefore, I suggest using pre-trained word embeddings like word2vec, GloVe or fastText, which have been trained on gigantic samples of text. More recently, transformer models have upped the game. They are large pre-trained networks that can produce contextualized word embeddings taking into account the surrounding words/context. I highly suggest looking into large language models (LLMs) to understand their full power, see further details here.
At Earlybird, we’ve been exploring multiple “make” avenues but found it incredibly helpful to leverage the expertise and products of our portfolio companies Aleph Alpha and thingsTHINKING for this task.
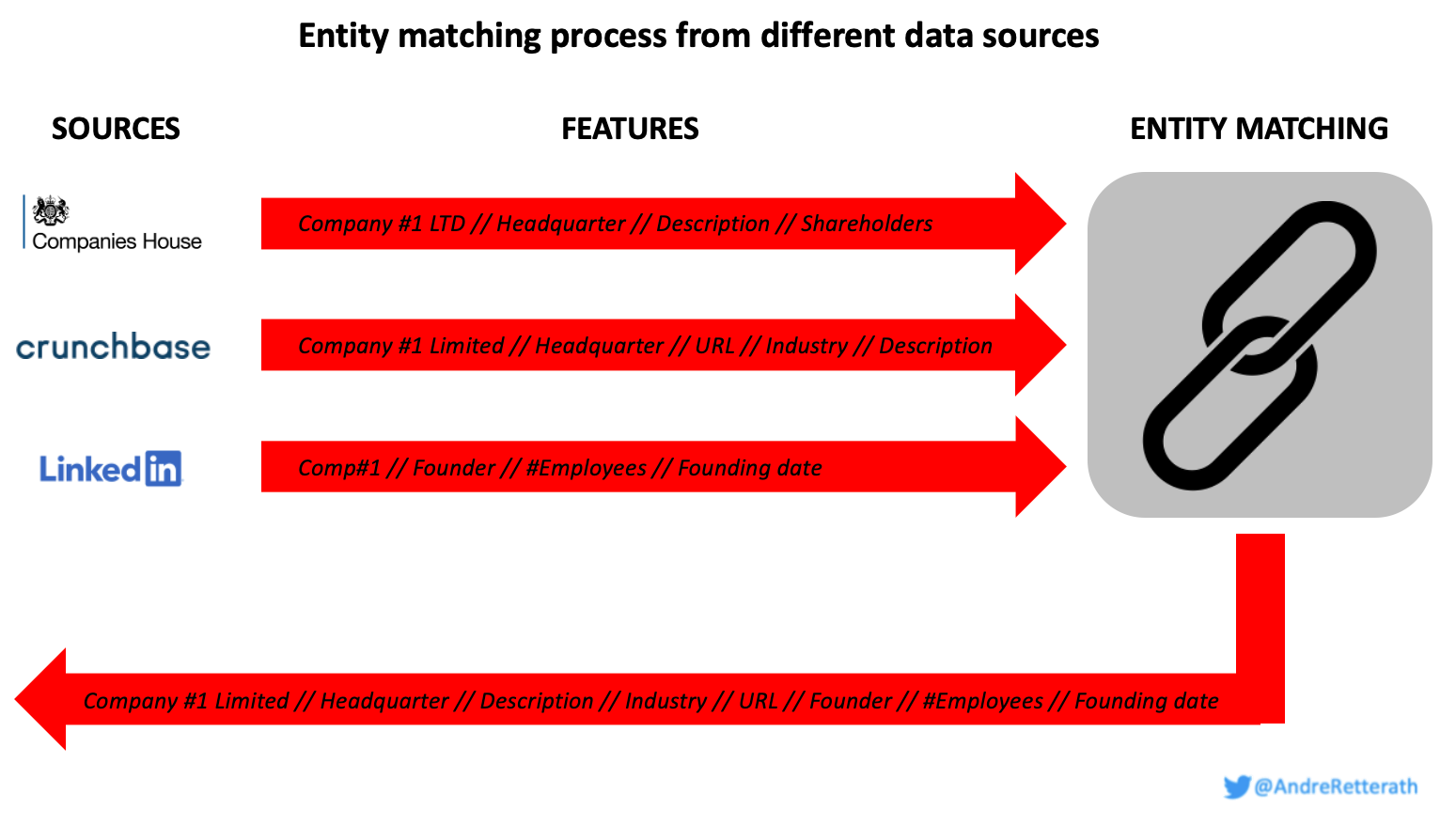
By starting with rule-based fuzzy string matching and gradually adding deep learning-based matching approaches, we eventually get closer to our goal of “including every company once, no more and no less”. Hereof, we face problem 2. “Redundancy in features for the respective companies” as described in the beginning. In line with problem 1. and the example of the three data sources CB, CH and LI above, we just need to substitute “company” with “feature”:
As a result, many
companiesfeatures are included once, some of them twice and a few of them even in all three datasets.
Different from the company entity matching, however, we cannot just merge all features together. Although it might be the same feature in terms of the label, the values of the respective feature might differ across data sources. In line with the example above, CH and CB might both contain the feature “description” but for CH the value might be “B2B enterprise productivity software automating repetitive workflows” and for CB “RPA workflow automation platform”. This raises two sequential questions:
How to deal with a) duplicate or b) different features of the same company?
For a) duplicate features of the same company, I prefer to store all values with their respective source, for example in tuples of (value:source).
For b) different features of the same company, I prefer to just append both/all different features.
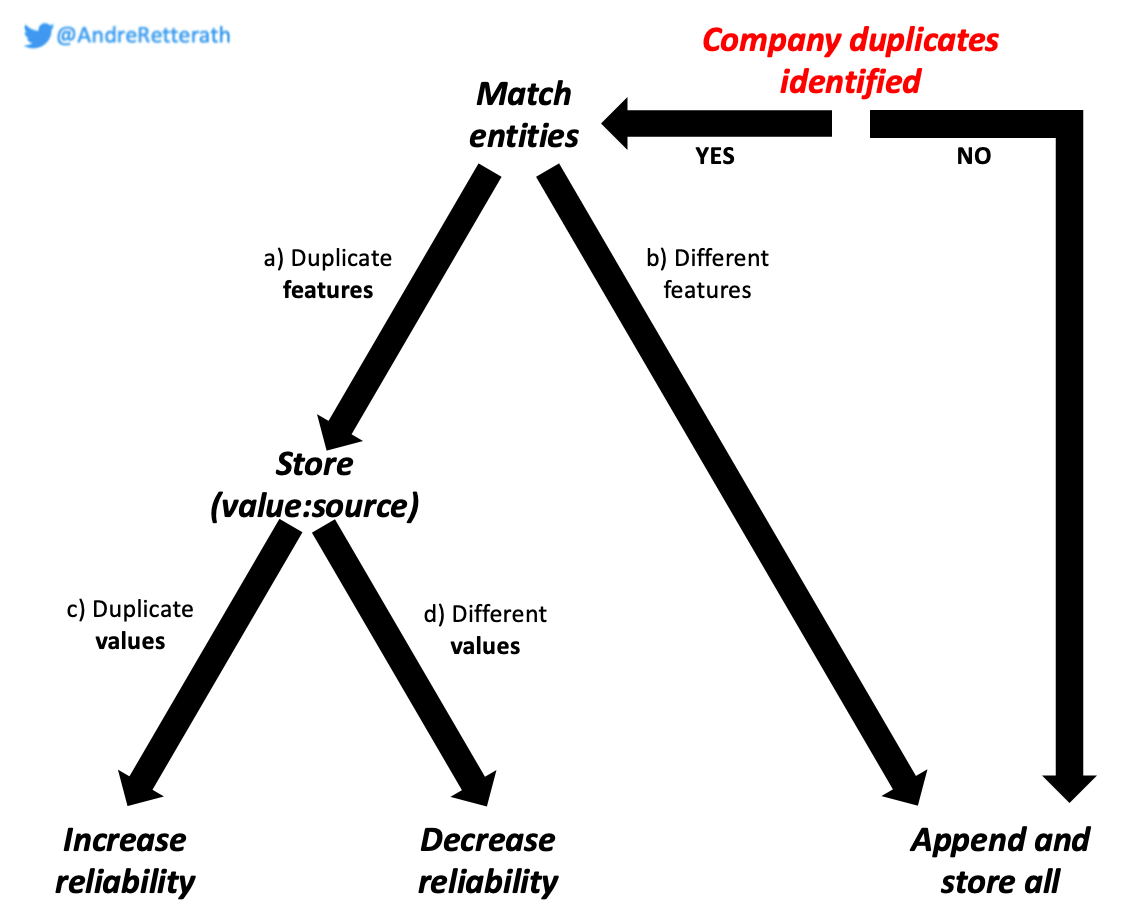
How to deal with c) duplicate or d) different values of a) duplicate features of the same company?
For c) duplicate values of duplicate features of the same company, I see it as confirmation/validation of the respective value. The more duplicates of the same value, the higher the credibility and reliability of the respective feature.
For d) different values of duplicate features of the same company, I typically rank the values according to a manual credibility score of the respective data sources. For example, one could argue that TechCrunch is more credible than Twitter. In a scenario of different values, TechCrunch would be prioritized while still decreasing the overall reliability of the value due to contradicting or different values in the first place.
Following the above steps, we can finally remove company duplicates and merge all entities into a single source of truth. Adding a variety of alternative sources, we boil it down to one single entry per company while appending all features, thus getting a more comprehensive picture of the company itself. Moreover, we can leverage identical or different values of the same features of the same company to assess the reliability of the respective features.
Finally, the groundwork is done. Now that we have achieved comprehensive coverage top of funnel with a single source of truth, I will dedicate the next episodes to data cleaning, feature engineering and the universe of different screening approaches to eventually cut through the noise and spot the most promising startup opportunities.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Hey Andre, we have actually had a few VCs approach us recently with the same idea to do this in Tilores.
Since you get the topic of entity resolution (I wish there was only one term for this!) Maybe it would make sense for us to have a chat? Maybe in-person if you're in Berlin.
Very well written! Thank you for sharing your journey with the community!
However, out of curiosity, I wonder how big an impact will the duplicated records have on the down streams?