

Data-driven VC #3: Make versus buy + the best database to start with
Data-driven VC #3: Make versus buy + the best database to start with
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 1,335, +201 since last week
Tl;dr
You need a GP sponsor (!)
Follow a clear framework to answer make versus buy
Go for a hybrid setup as it provides high independence with low maintenance at manageable costs
Do your homework and compare commercially available datasets to identify the best entry point for building your own solution; Crunchbase delivers the best value for price in terms of startup datasets
Gradually complement the foundation with additional identification and enrichment sources
“Venture capitalists (VCs), who fall into the class of individuals and institutions that manage private capital assets, and private companies share a common denominator: the majority of their data are kept private”. This sentence was not only the introduction of my PhD dissertation on “ML and the value of data in VC” but also the most frequent argument for why the majority of VCs did not believe in data-driven approaches a few years back. Adding that “data is hard to collect, sparse, not reliable and biased”, it felt to me more of a protective behavior of the old VC world rather than a logical argument to not even try.
Thankfully, “the data guys” started to experiment and sentiment has shifted as we hear from our Limited Partners (LPs) that a growing number of VCs nowadays claim to be “some kind of data-driven”. So in less than five years, perspectives flipped from “no way, impossible, doesn’t make any sense” to “yes, of course, obvious”. While the long feedback cycles and the lack of immediately tangible results historically prevented most VCs from significant upfront investments into engineering teams, datasets and infrastructure, the growing competition among VCs together with LPs proactively asking for the VC’s data-driven initiatives started to spur this movement.
Although IMHO the majority of VC firms are rather window dressing today, i.e. some fancy slides in the fundraising deck and having a working student stitch together some datasets, I believe it’s still day one and urge everyone to manage expectations. Only with a healthy balance between promise (fundraising slides) and reality (what’s under the hood), we will fulfill expectations and gain the required freedom to explore and transform the whole VC industry.

Make versus buy?
The question has multiple dimensions and I’d like to structure the four most important once in a top-down sequence:
Fund size and General Partner (GP) sponsor: The fund size together with the management fee (typically 2-3% of the fund size p.a.) defines the available resources to operate a fund. Deduct costs for office, team, travels, due diligence, equipment, etc and you’ll end with the free resources. While for smaller funds there is oftentimes not too much left, larger ones might end up with a profit that is either distributed among the General Partners (GPs) or available for investments into the future of the firm.
From my own and many befriended data-driven VCs’ experiences, I can tell that make or break for a proper data-driven strategy (as for many other upfront investments into long-term firm initiatives) is at least one sponsor among the GPs. Why? Because if they are short-term oriented, they will always cash out the remainder of the management fee whereas only long-term oriented GPs are willing to invest in the future of the firm. Assuming a long-term orientation and a GP sponsor for data-driven approaches, the result of the above calculation defines whether a VC needs to buy external solutions, i.e. if few resources are available you need to go for a cheaper but less sophisticated and distinguished solution) or has the resources to build in-house.
Value creation and dependency: Build core and buy non-core. For the sourcing and screening part, the value creation from an engineering perspective increases from beginning to end. Starting with the data collection, we can either buy more comprehensive datasets from commercial aggregators like Crunchbase, CBInsights, Dealroom, Pitchbok and co or leverage more focused crawling services like Phantombuster or APIfy for social media data and other more specific sources. All of them bear little downside risk as there is lots of redundancy - if one service shuts down or changes its pricing, you can replace them fairly easily without too much of an impact on your overall processes. Other than from an economic/price standpoint (external crawling services can become very expensive over time/volume), there is little reason to collect broadly available data yourself.
Only thereafter begins the actual value creation in the entity matching where we need to tie all datasets together, remove duplicates and make sure we obtain a single source of truth. This is crucial and I prefer to keep this in-house. Even more important is the following feature engineering and the training of the screening models. These signals steer investment professionals to the most promising investment opportunities and are the core of a data-driven strategy. It’s the secret sauce and in the case of external solutions hard to replace as you never know what’s under the hood. Consequently, I prefer to keep the respective efforts in-house.
Maintenance: While keeping everything in-house would be the most sought after solution in terms of value creation and dependency, we need to keep in mind that the more we insource (outsource), the higher (lower) the maintenance efforts. This question is specifically relevant for the data collection as running your own crawlers does not only require a proper proxy server infrastructure but also needs continuous adjustments to the crawlers themselves. Whenever a button is moved on the target website, we need to adjust the crawlers (or come up with an abstraction logic to scale them).
Short-term versus long-term: Buying a one-stop solution like Specter, Koble or Zapflow is overall cheaper than building everything in-house and delivers good short-term value, whereas building in-house is generally more expensive and takes longer. However, in-house likely exceeds external solutions in performance and value add as you can tailor it to your specific needs. I prefer a hybrid of buying external one-stop offerings (or as few products with as much value as possible) to start with and gradually replacing them with in-house solutions.
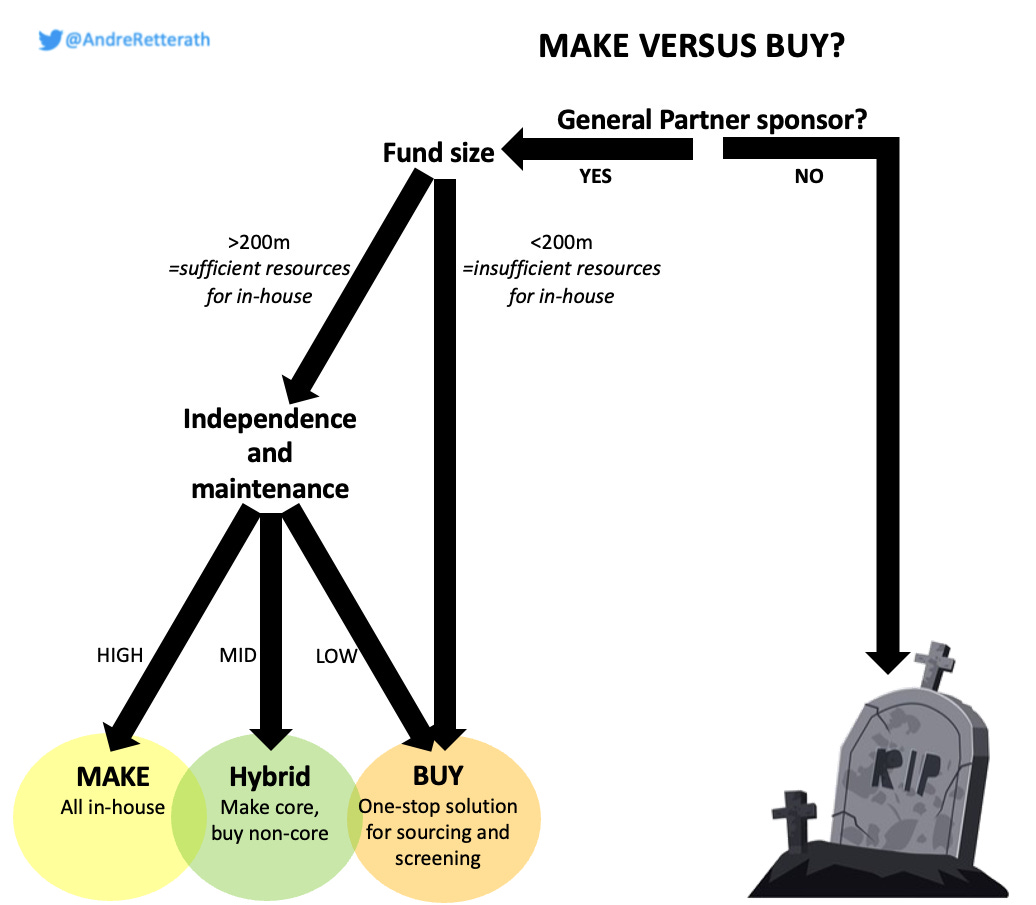
So you might wonder: What does that mean for your specific situation? Assuming GP support, I would cautiously frame the following rule-of-thumb:
Fund size >200m —> Start with buying a one-stop solution to add short-term value; then build up internal engineering capacities, buy the most relevant data sources (follow the 80/20 rule, there is lots of redundancy), crawl data that is specifically relevant to your investment focus (think Github, Appstore, ProductHunt etc) and shift to a hybrid solution where you keep the core (the entity matching, feature engineering and the subsequent model training) in-house to reduce maintenance efforts but keep long-term independence. Full in-house IMHO is to heavy on maintenance and there is no need to reinvent the wheel but rather rely on existing database providers as long as there is redundancy available.
Fund size <200m —> Just go ahead and buy a one-stop solution.
Where to start?
As said before, for the short-term value it makes sense to buy one of the one-stop solutions mentioned above. I personally don’t know them very well but want to review the most famous ones in more detail in one of the next articles, so if you have exposure and a perspective on them, please reach out! :)
On this basis, we can then think about our move ahead to a hybrid setup, starting to split up the major two components of data collection (identification and enrichment) and screening. With respect to the data collection, I personally followed an 80/20 approach and asked myself the question “Where can I find reliable data (accuracy) on the majority of companies (coverage) at the lowest cost (value for price)?” To answer it, I conducted a startup database benchmarking study in 2020; quick summary below:
Purpose: Identify the best startup database
Databases: Angellist (AL), CB-Insights (CI), Crunchbase (CB), Dealroom (DR), Pitchbook (PB), Preqin (PQ), Tracxn (TR) and VentureSource (VS, which got recently acquired by CI)
How: Compare actual information on 108 startups that received 339 financing rounds from 396 globally active VC partnerships between January 1, 1999 and July 1, 2019 with their representation in the startup databases
Method: comparison of descriptive statistics, frequency distributions, logistic regressions
Dimensions (selective overview):
General company information: Headquarters, industry
Team information: Number of founders per company, highest degree of founders
Financing information: Number of financing rounds, round sizes, participating investors, valuations, total raised, date of the financing round
What is the best startup database?
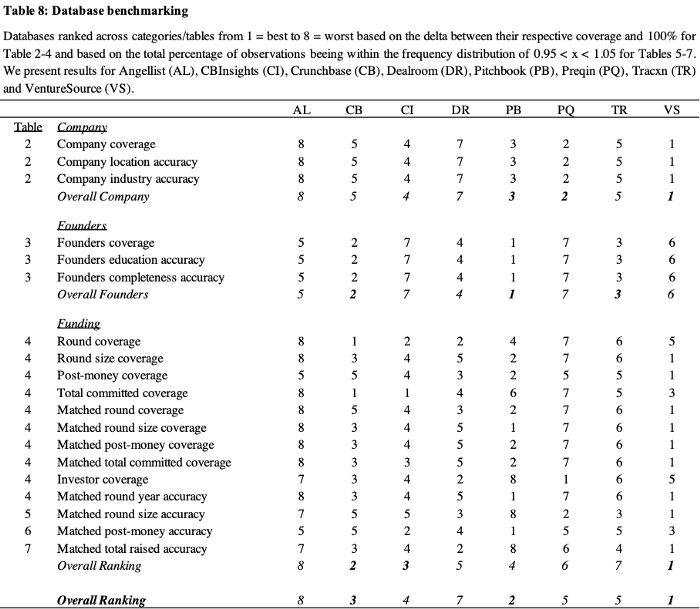
The below graphic exhibits the aggregated results of our database benchmarking from 1=best to 8=worst across the different dimensions considered in the descriptive statistics. VentureSource (VS) seems to have the best coverage and quality across all subcategories of general company information. Similarly, Pitchbook (PB) has the best coverage and quality across all founder-related categories. Although VS, generally speaking, seems to provide the best coverage and quality in terms of funding information, we find that Crunchbase (CB) dominates coverage in terms of rounds reported and total capital committed.
In summary, our analysis reveals that VS, PB and CB have the best coverage, and are the most accurate databases across the dimensions of general company, founders and funding information. A combined dataset with the best possible coverage would consist of general company information from VS, founder information from PB and funding information from a combination of CB, PB and VS. Considering that CI acquired VS in July 2020 after Dow Jones has ceased their operation of VS in April 2020, I’d say: Nice move, Anand ;)
As previous studies show that companies which are located in specific geographies, which operate in specific industries or which have achieved later financing stages are more likely to be included than others, we subsequently examined the determinants of a company, founder, financing round, financing round size and post-money valuation appearing in the databases. Although a specific database might be the most comprehensive and most accurate, it might still have biases and only include specific types of startups which make it less useful for certain purposes.
Consequently, the results of our “sampling error analyses” are highly important if you look for companies in specific geographies, industries or stages. While the details of our results would easily go beyond the scope of this summary blog post, we find in general terms that greater financing rounds are more likely to be reported than lower ones. Similarly, financing round sizes and post-money valuations are more likely to be reported for greater financing rounds than for lower ones. Concerning the detailed results, I highly suggest reading our original study when selecting a startup database to work with.
To wrap up, different databases have different strengths and weaknesses. A combination of CB, PB and VS/CI leads to a comprehensive and accurate dataset. In terms of value for price, CB is certainly the best pick based on the results of our study, hence I suggest to take CB dataset as foundation and build on top.
In the next episode, I will explore avenues on how to complement the foundation (CB in this case) with further identification and enrichment sources (see the previous post for more details on the respective categories).
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Wow, great information. Thank you once again Andre. So amazing to find someone who has been thinking about/researching this problem set. I took a different approach because I am an industry analyst. I wanted to answer different questions, such as:
-How many cybersecurity vendors are there? (Still don't have that answer, after 17 years. :-) It's a moving target with acquisitions, failures, and startups every year, but there are 3,032 in our database this morning.)
-What is the country distribution? (52.8% are in the US)
-How many in each of 17 categories?
-How fast is each growing? How fast is each *segment* growing or shrinking?
-Investments (there are 2,200 investors in 1,560 companies)
Then comes the enrichment, pulling in more datasets.
Then build a tool that allows me to filter/search/sort and export.
I have one question about your comparison of data sources. In all of these tools it is easy to find a vendor by name. If you start with a list of 108 then they are great tools. How do you generate that list? What if an investor wants to understand a particular market? Did you test their ability to give accurate search results? In cybersecurity for instance: "Find all the API Security vendors." Or, more refined: "Find all the API Security companies with 20-40 employees and less than $20 million in investment." Pitchbook cannot do this.
It took us years to find all the companies we print in Security Yearbook every year. Just to categorize them took over 4,000 hours of my time over the last five years!