

Data-driven VC #27: The Power of GPT-4 & LLMs in Venture Capital
Data-driven VC #27: The Power of GPT-4 & LLMs in Venture Capital
🔥 A guide to AI-based startup sourcing by Leadspicker

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 6,700+, +140 since last week
Brought to you by Affinity - Find, manage, and close more deals with Affinity

Affinity Campfire brings together industry-leading dealmakers to explore what it means to be a part of the leading relationship intelligence ecosystem. Dive deeper into the importance of data-driven sourcing and what dealmaking will look like in 2023 as we navigate a changing global landscape.
What a crazy week 🤯 I don’t want to be the next smartass analyzing what has happened, but please let’s take this whole SVB thing as a warning shot and be more thoughtful about how and where we deposit our money in the future. It’s our responsibility as VCs to not forget about it and advise founders accordingly.

Learning our lessons and leaving SVB behind us, let’s get back to the fun stuff: Generative AI! Two days ago, the long-anticipated GPT-4 model got launched by OpenAI. My first impression? Surely incredible advancements, but not as mind-blowing as I personally expected.
On the pro side, we got an increased word limit, more creativity, better reliability and accuracy so that it can ace standardized tests, but on the con side, the model still hallucinates and can be hacked to bypass its guardrails. And the multi-modality? Well, our portfolio company Aleph Alpha invented and launched this as part of their model MAGMA in April 2022, so it’s really just a functionality catch-up for OpenAI.
The most concerning? I’m disappointed that OpenAI, which started as an open-source non-profit organization, has become closed-source and puts profits over the community. No details about model architecture, size, training infra etc. have been disclosed yet. But that’s a topic in itself..
Independent of these concerns, the impact of large language models (LLMs) will be significant all across and for me, it’s actually less about the pros and cons of a specific model version from a specific company, but more about the gradient of innovation in AI more broadly. Just extrapolate recent developments by another year or two into the future..
..which makes me think again about the impact of LLMs on our industry. Following my “10x your productivity with ChatGPT” and “What ChatGPT means for the future of startup funding” posts earlier this year, Vlasti, one of my readers kindly reached out and shared some valuable perspectives on how his team incorporates LLMs into startup scouting workflows. Some fruitful conversations later, I’m incredibly excited to have Vlastimil Vodička, CEO and Founder of Leadspicker, share his “Guide to AI-based startup sourcing” with us in the guest post below.

By reading this post, you will learn:
What data sources do we use and how to scrape them
How you can get data from LinkedIn (and don’t get your account blocked)
How to utilize Machine Learning (ML) to distinguish between a startup and an ordinary company
The role LLMs play in our stack, along with an example of a prompt
What's new with OpenAI GPT-4?
How do we find up-to-date founders' information and verified contact details
We have tested many tools and LLMs and in this post, I'm going to share with you the secret sauce that powers Startup Scout by Leadspicker, allowing us to discover and categorize over 100,000 new unique startup companies each year, months before they become visible in any database such as Crunchbase,
Since 2016 we have completed 750 scouting projects in 42 countries, helping to identify and approach the most exciting projects out there. Over the years, this process has been refined and optimized to the point where it has replaced 35 analysts (interns/students) who previously helped us manually research and clean data, making the sourcing process very cost-efficient and effective.

Challenges of AI-based startup scouting for VCs
Researching new companies to expand your deal flow funnel can be challenging and time-consuming. There are several pain points that you can experience:
Identifying the right data sources for scouting can be quite a challenge with so many options to choose from. While traditional Crunchbase-alike platforms such as Dealroom, Pitchbook, and Tracxn can be great starting points (thankfully Andre shared his database benchmarking results here), it's important to remember that most founders, especially those outside the US, don’t create profiles on Crunchbase as the first thing when starting their company. Instead, public sources like LinkedIn, Facebook groups, and other online communities can be a much better resource for discovering new, promising firms.
Finding good quality and relevancy is especially important in VC, as the screening capacity is always limited and hard to scale. Also, it's important to keep in mind that what defines an interesting company can vary from fund to fund. For example, an impact or a food-oriented VC fund might have a different scope than a B2B SaaS or FinTech fund. So, it can feel like searching for a needle in a haystack when you're trying to find ideas that fit specific niches or technologies.
Right people with contact details: When researching relevant startup companies, it's essential to effectively identify also the key personnel in charge, typically the founders, and their contact details. This is especially important for funds with an active deal-generation approach
Deduplication and data merging: When using multiple sources, it's common to discover the same company from different web pages. To avoid duplications and ensure that you are not rediscovering companies and people that you have already found, it's critical to keep your data clean and organized through deduplication and data merging. Andre has shared some valuable learnings on this here
Timing is crucial when searching for new founders since there is a limited window when a researched company is most relevant and being the first to identify and approach them can give you a competitive advantage over other funds.
When running an outbound outreach, the key is to ensure high personalization, deliverability, open rate, and reply rate by using the right tools and techniques.
Blacklists and Deconfliction Rules: Operating across different funds in multiple industries or countries requires implementing blacklists and deconfliction rules to ensure that you don't reach out to people you shouldn't. This includes not contacting people who have already been contacted by your colleagues.
Ensuring scalability and consistency is critical for staying competitive. The key is to implement the right tools and systems to manage and organize data and automate processes as much as possible.
The rising costs: Improving the effectiveness and automating or streamlining processes is cheaper and more effective than hiring more people.
Leveraging ML to empower human intelligence
At Leadspicker, we've built a unique data-driven sourcing process that connects the dots between the latest technology and human expertise to deliver efficiency and accuracy that was not achievable a year ago.
We reviewed many novel tools, including all OpenAIs’ and others’ newly released LLMs. Our process has been refined over the years to enable us to generate deal flow from all over the world. In the next chapters, I'll uncover our process step-by-step, which is also illustrated in the picture below, and share the technology we use at each stage, along with its benefits.
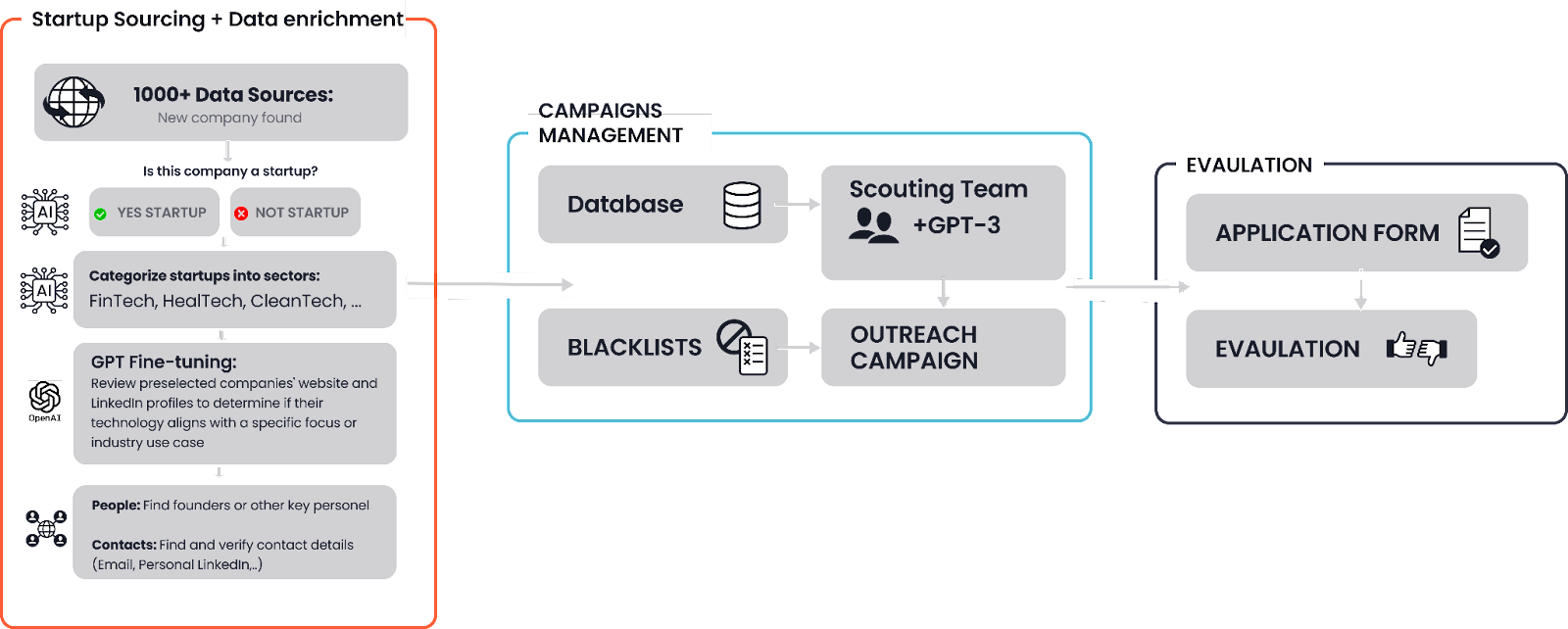
Each part of our above-shown process plays an important role in identifying and connecting with the most promising projects worldwide. In the next paragraphs, we'll guide you through the startup sourcing process step-by-step, explaining where our data comes from and how we find relevant and up-to-date information including contacts on founders.
Discovering the data sources: Where to find input datasets for next-gen AI models
We gathered over 1000 data sources (find an overview by Andre here) to find new companies from around the world. I know, that’s a lot of data. But with the latest developments in scraping tools such as Apify or Browse.ai, you can do it too!
One of the most important data sources for us is LinkedIn. We leverage LinkedIn to find anyone who has recently set up a job title as “founder” OR “co-founder” OR “CEO” or “CTO”, and other relevant positions.
The use of LinkedIn data enables us to identify:
All new founders (< 1 month) in a given geography
Operators from your portfolio companies who have left to start something new
Diaspora or alumni from prestigious universities who are running a new company
Ex-high-value company employees who left and became founders
Here is the list of the most relevant data sources
Regularly monitored data sources:
LinkedIn profiles of anyone who has recently set up a job title as founder, co-founder, CEO, COO, CTO, or who is working in stealth mode in a fresh company
Major global databases: We use Crunchbase alike platforms as well as directories such as Product Hunt and crowdfunding platforms, to discover new and emerging companies. If you don’t know where to start this could be a great starting point:
Minor (local) startup directories: We also use smaller, more localized websites that focus on specific regions or industries that might be overlooked.
Tech media: We also monitor media outlets and blogs like TechCrunch, and Sifted, as well as local outlets like CzechCrunch to stay up-to-date on the latest trending companies in the world.
Relevant Facebook groups and other communities: We leverage Facebook groups and other online communities to identify founders and other key personnel. Example: https://www.facebook.com/groups/AustrianStartupPinwall/
Ad-hoc data sources:
Conference networking apps: We use apps that are designed to facilitate networking at tech conferences, which can help us to identify new companies and connect with founders and investors. After the conference, we create a list of attendees (usually consisting of name, company name, and company type) from the app. Then we use our tools to enrich this data with the right URLs, LinkedIn profiles, contact details, and other relevant information.
Portfolio of incubators, competitions, accelerators, and other VCs: We explore the websites of these organizations to identify firms that they are working with or have invested in, which can provide valuable insights into new and promising companies.
Scraping and crawling private and public data
It's not rocket science, but it does require some technical expertise. We are fans of Python packages for web scraping, such as Scrapy or Selenium, which provide basic code snippets.
Andre wrote an insightful piece on “how to scrape alternative data sources” here and you can find another helpful post on this topic here. Additionally, forums like Stackoverflow offer threads that provide complete code for scraping a specific data source. Also, there are many out-of-the-box scraping tools and services like Browse.ai, Apify, or Phantombuster that could be good enough for a small-scale use case.
Our data scraping process allows for a quick turnaround time of adding new data sources within just a few hours of creating a ticket. This is helpful if you need to expand your reach and identify emerging companies, for example in regions previously not well covered, such as Africa or Southeast Asia.

*The split of industries is based on 2021-22 data and is significantly influenced by the COVID-19 pandemic. ** The individual categories were chosen according to the application form at https://apply.techstars.com
What tools for scraping LinkedIn?
We're all familiar with the fact that extracting information from LinkedIn is a challenging task when you do it by hand. This is where automated tools come in handy. By scheduling data collection and notifying you of any changes, you can save time and effort. If you only need to cover a small scale or don't require frequent updates, tools like DuxSoup, and Phantombuster, can help you scrape LinkedIn data efficiently.
IMPORTANT: Automating your LinkedIn actions can lead to banning or losing your accounts, but when this happens is unpredictable. LinkedIn is not very consistent as to when they block your account.
Anyway, here are some recommended max limits for LinkedIn Profile page extractions
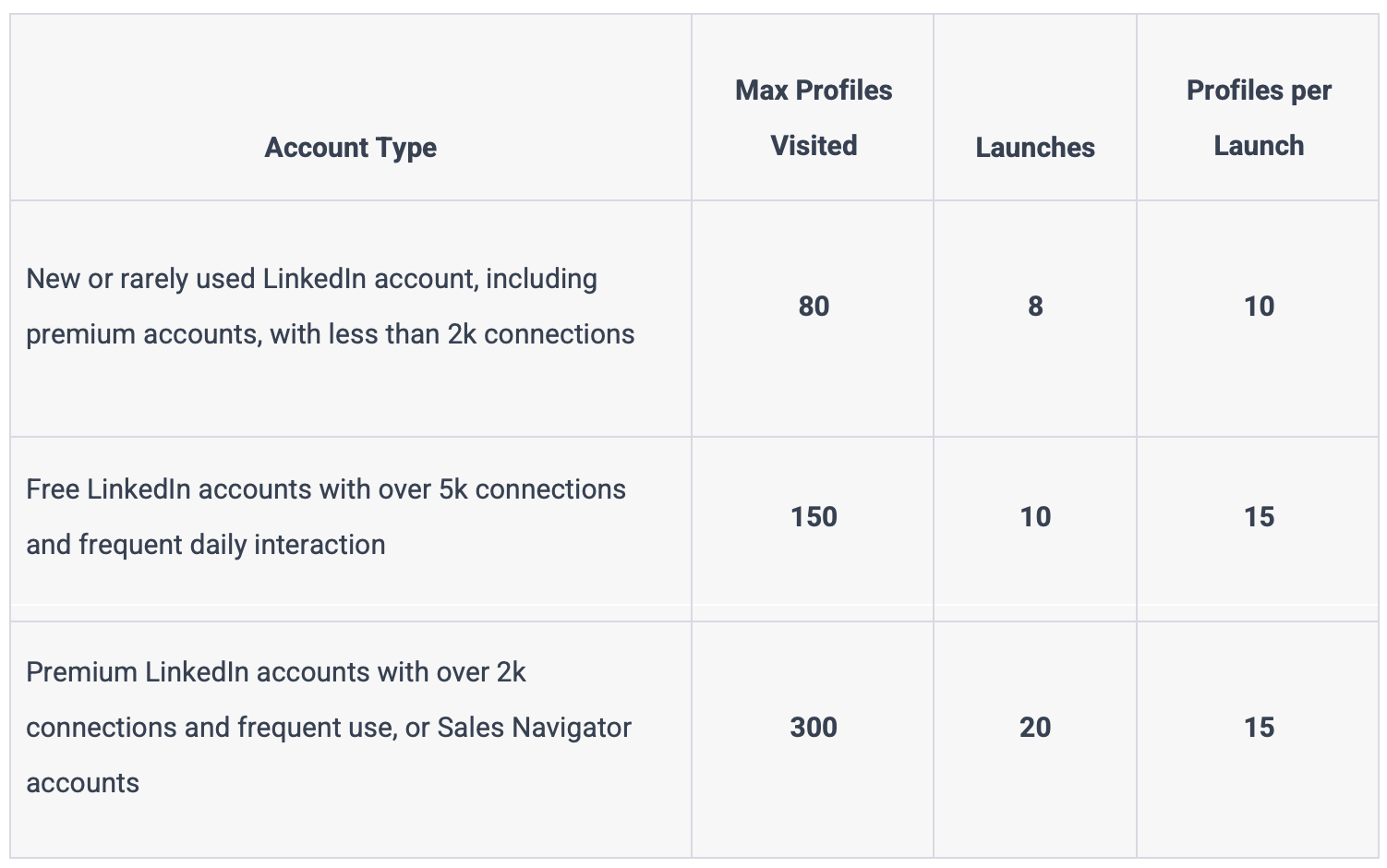
How to extract data from LinkedIn on a larger scale?
Any of the above-mentioned LinkedIn automation tools aren’t scalable and cost-efficient for larger-scale use cases. But do you know who the biggest scrapers out there are?
Search engines! We can leverage them to scrape public LinkedIn profiles even without a need for a LinkedIn profile or being even signed in.
Especially when we were building our new SaaS tool Pipebooster.io, we learned that we can utilize various “hacking” methods to scrape public LinkedIn profiles that have been indexed by search engines (Google, Bing, DuckDuckGo, Yandex, Seznam). By using a cascade of search queries, we can narrow down outcomes on the results page to show only what we need.
Example of a simple search query:
site:linkedin.com/in/ intitle:"CEO" OR "Founder" AND Company XYZ

Benefits: We receive a comprehensive and constantly growing stream of new companies. This provides us with a large pool of companies to analyze and evaluate while also allowing us to easily and quickly expand our reach by adding new sources as needed.
Challenges: It's important to note that not every new company is a startup and the “relevant versus irrelevant” definition may differ from fund to fund. With millions of new companies every year, it would be impossible to manually determine which ones are a fit. That's where our advanced technology and processes come in. We will elaborate on this in the next section.

AI-powered classification
Ok. So now we have a lot of data from various sources. But it’s too much data for the human investment professional to be able to go through it all. This is where AI comes in handy.
The next step is to identify which of the companies that you found are startups and which are most probably not (marketing agencies, advisory firms, kebab kiosks, ice coffee shops..) and which of the most frequent industries it belongs to.
In the next chapter, I will describe how we trained our own (economic) machine-learning algorithm that has been then finetuned with (costly) OpenAI’s GPT.
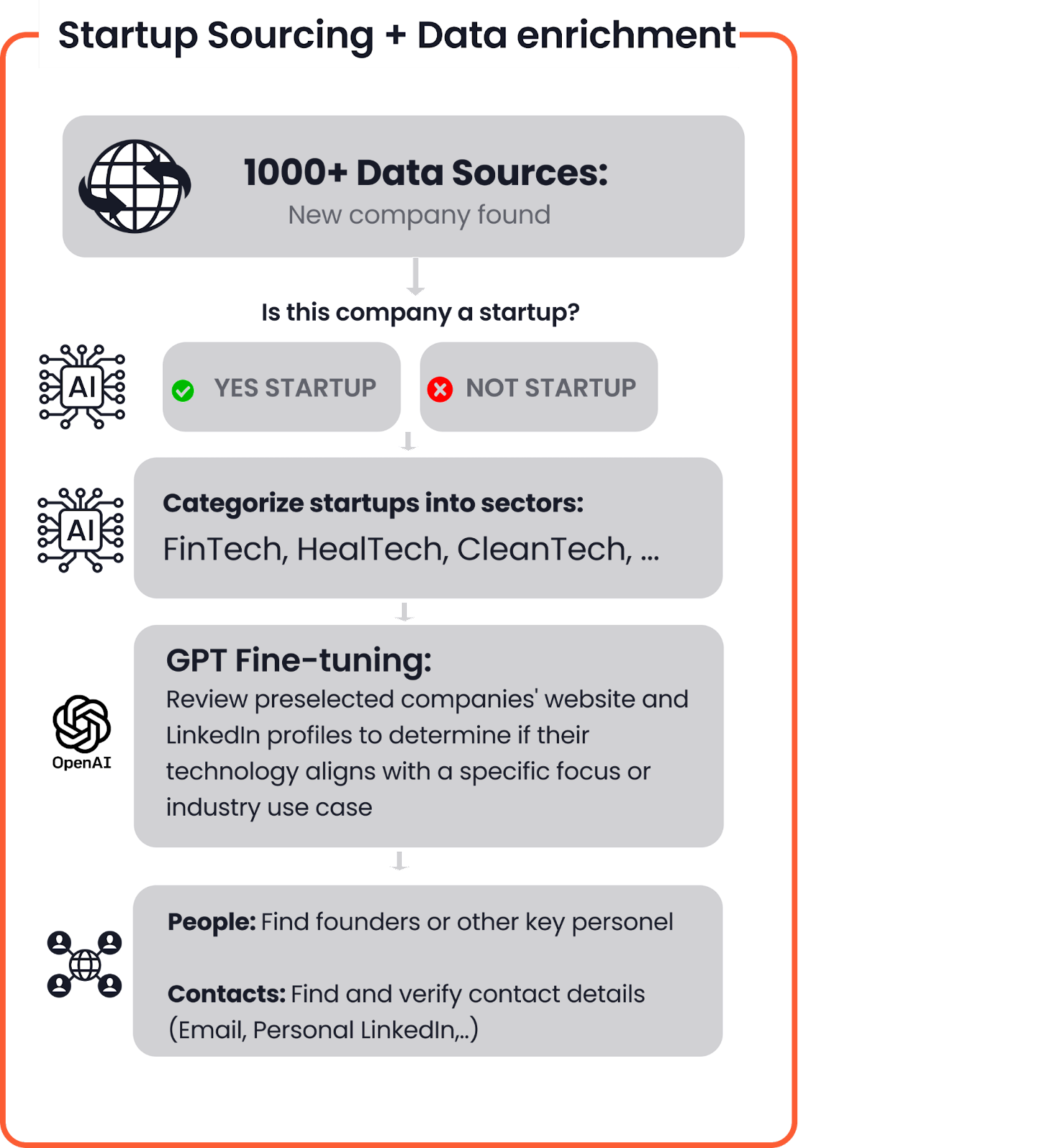
As mentioned before, different funds may have varying criteria for identifying relevant deal flow. For instance, a food tech or impact accelerator may have a different understanding of an interesting company compared to a B2B SaaS investor that focuses on high-growth software.
Save costs and optimize efficiency: Train your own ML classifier to filter out irrelevant companies
Using LLMs to analyze tens of thousands of websites can become very expensive, especially if you have a lot of data sources to process and considering that the majority of the researched companies are likely irrelevant.
That’s why we have trained our own ML classifier. To classify whether a company is a startup or not, we use an advanced ML model called XLNet. XLNet is a state-of-the-art NLP model that has been shown to outperform other language models like BERT in tasks such as question answering, sentiment analysis, and document ranking.
We trained the XLNet model on a dataset of 8 million companies that were tagged by our team of 35 interns over the past 7 years. To tag such a large number of companies, we developed our own data tagging console along with a Chrome extension that automatically loads and opens websites and LinkedIn profiles for each company. This frees up our interns to focus solely on evaluating and tagging the data.
In our process, we not only classify whether a company is a startup or not but also categorize it into one of 32 general industries, with the possibility for a company to belong to multiple industries.
The advantage of owning an ML model is that once it’s well-trained, you don’t need to pay any external provider such as OpenAI. So you pay only for infrastructure costs which is very economic.
Interesting facts: On average, each person using our data tagging console and chrome extension was able to evaluate around 200-300 websites per hour. To tag 8 million companies, we invested a total of 32,000 man-hours into data tagging. To put it in perspective, this is equivalent to 35 people working full-time for 5 months.
Challenge: It is very difficult for people to maintain focus for hours, and as a result, the generated dataset is very generic and may not be 100% accurate. However, this process allows us to cost-efficiently filter out most of the irrelevant companies before they get input into GPT.
GPT and other LLMs: Transformative tools for company categorization
A few months ago, training new XMLNet-based ML classifiers that select only companies that are aligned with each fund's focus on a specific industry, business model or technology would have been a challenging and costly task.
However, we have found out that unlike GPT-2, the latest 2022 and 2023 versions of OpenAI's GPT models (3. and 3.5) are already effective tools for accurately categorizing and classifying companies based on summarized content from a company's website and LinkedIn description.
And now, after some rumors, GPT-4 got finally released! As it is really easy to switch between OpenAI's models, we tested it immediately after the release.
What's new with GPT-4?
Increased word limit (from 3000 to 25 000 words)
Knows more languages than its predecessor
Improved "intelligence" as it scores better than 90% of candidates in the Bar Exam (according to OpenAI).
Understands image input
Accuracy - GPT-3.5 would sometimes invent answers. The new models should be a step forward as it is 82% less likely to respond with inaccurate answers
Speed (however I was not able to confirm this, as it seems that it heavily depends on the complexity of the answers)
While GPT-3.5 proved adequate for analyzing most industries, we found it sometimes unpredictable, particularly when analyzing large volumes of websites. Our initial tests with GPT-4, which is easy to switch to for developers using OpenAI's models, produced better results for more complex industries, such as social impact businesses.
We also observed that GPT-4 is more consistent and accurate than its predecessor. In conclusion, the new model further enhances our process, as it can address gaps and edge cases that GPT-3 struggled with.
Fine-tuning with Open AI’s GPT API (3.5 & 4)
Thanks to the API of pre-trained GPT models, there is no longer a need to train new ML classifiers. Instead, you can create prompts specific to each fund and feed the GPT models via API with the website and LinkedIn profile of each company. This allows us to determine whether they fit even the most specific use cases.
To obtain this data, we have developed our own web scraping robot that visits each company's website and looks for sections such as "about". It then scrapes and summarizes the relevant information for further analysis.
Classifying millions of websites directly with OpenAI GPT-4 would be a very costly and inefficient approach since the price of each request is calculated in tokens based on the length of the prompt + the length of the answer. As a result, analyzing companies that are most likely irrelevant would still use up a considerable amount of tokens.
However, with the help of appropriate prompts, we have been able to fine-tune the results of our XLNet-based models through the GPT-3 API in a cost-efficient manner to customize each search according to the specific requirements.
Example of a typical process - looking for a specific BioTechnology:
Client’s request:
Find biotech startups that are working on eliminating the need for animals in the food production process.
How we proceed:
We first filter out non-startup companies and select only those within the biotech industry (categorized into the most frequent industries using our pre-trained XLNet-based algorithm)
This usually narrows down the list from millions of new companies to just a few thousand companies that might be relevant biotech companies
Then, we use the GPT-3 API to directly feed in summarized website content and Linkedin descriptions for each shortlisted company directly from our internal data portal.
With a specific prompt tailored to each unique use case, we ask GPT-3 to determine whether each company is working on the requested technology. For example, “eliminating the need for animals in the food production process”.
In the last step, we find the founders and get their contact information
GPT prompt example:
Prompt: “Review the company website and short description provided and answer the following question: Is the company a biotech company that is working on eliminating the need for animals in the food production process?
If YES, respond with "YES RELEVANT".
If NOT, respond with "NOT RELEVANT".

Interesting fact: It not only speeds up our sourcing efforts but also provides us with more accurate results than what human analysts can achieve.
The key difference lies in focus: While humans are great at understanding client context and fine-tuning prompts for the AI. However, they tend to lose focus and become disengaged after just a few hours of screening. In contrast, the AI can keep repeating the process indefinitely once the right prompt is generated.
Email hunting: Enhancing company and team data
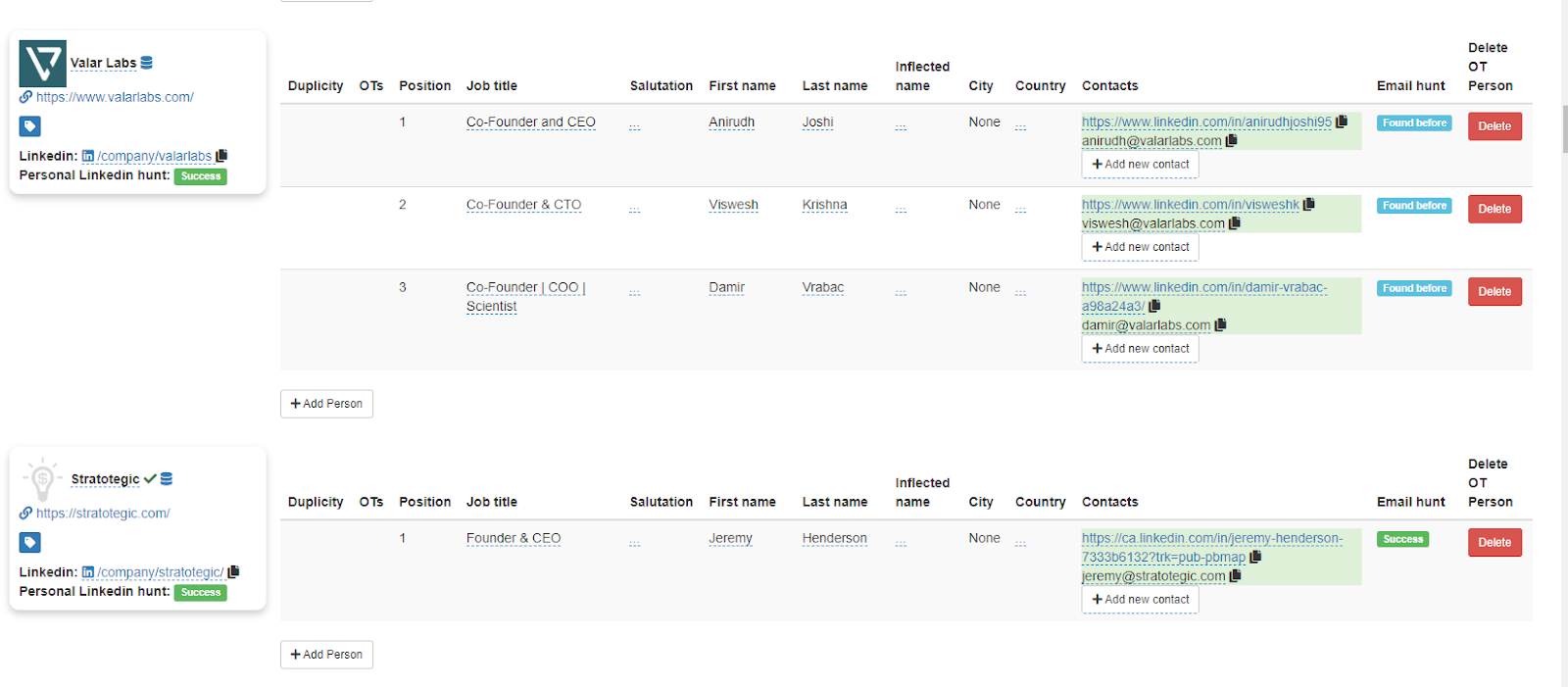
Now that we have a list of highly relevant companies, the next step is to identify the key founders behind these projects. We must also find and verify their contact information so it can be used in the active scouting process.
Below is a description of our data enrichment process:
Enriching company data with contact persons, finding verified emails of founders, their personal LinkedIn profiles, and other data points
All data are stored in one central location where they are merged, deduplicated, and missing data is enriched
Non-operational websites are automatically excluded
Important: It is crucial to ensure that you are only reaching out to active founders. Databases are not always reliable as they often contain very outdated information, including individuals who have already left.
As a solution, our system conducts real-time searches for founders and other key personnel using specific search query strings like:
"site:linkedin.com/in/ intitle: 'CEO' OR 'Founder' OR 'Owner' OR 'Co-founder' AND <Company Name>".
To find and verify the most accurate email addresses of researched founders efficiently, we utilize a combination of our proprietary email hunting tool, third-party providers, and the Zerobounce verification tool.
Our email hunting tool uses 32 common patterns to guess email addresses, and each step is verified by Zerobounce. If we cannot find or verify the correct contact, we automatically search for third-party data providers starting with cheaper ones and escalating to more expensive ones like ZoomInfo. At each step, Zerobounce verifies the contact. This entire process is automatic.
Conclusion
By reading this article, you have learned how we replaced the need for 35 analysts by utilizing technology, including our own ML classifier, GPT-based fine-tuning and search engine hacking. Our process has achieved efficiency and accuracy that wasn't possible a few months ago.
We believe that this is just the beginning. With the current rapid development of generative AI, we can expect more and more innovation also in the other stages of the investment process as well.
That’s it for today. Hopefully, this comprehensive guide serves as further inspiration for your firm to become more data-driven. Let’s leverage our growing community to learn from each other and eventually make our industry more efficient, effective and inclusive.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Hello Andre, thanks for the post and the work you are doing with this blog. Since you have mentioned Aleph Alpha a few times in your posts, I looked at their solutions. One thing I noticed is how much less intuitive their Playground is to use compared to OpenAI based solutions such as e.g. ChatGPT or Dall-E.
Is there a plan to establish an easy to use interface for the end consumer by Aleph Alpha, too?
Thank you and kind regards,
Laurenz
Hi Andre, super interesting. Very eager to build a similar data pipeline for B2B sales funnels. I imagine your funnel can be adjusted for sales quite easily - are you planning to offer this to startups? Cheers, Olli