

Data-driven VC #20: The VC digitization journey
Data-driven VC #20: The VC digitization journey
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 5,238, +325 since last week
I started this newsletter in September last year with a clear thesis in mind: VC is fundamentally broken and technology can help us fix it. Initially, I shared a variety of learnings from my PhD research as well as my own journey at Earlybird including an overview of different manual and data-driven sourcing approaches, the “make versus buy question”, the most valuable commercial database providers, a step-by-step guide to scrape alternative data sources, the different approaches for de-duplication and entity matching, the importance of feature engineering for proper success scoring… and a lot more.
While diving deeper into this magic rabbit hole in the intersection of VC and data, I occasionally shared some technically rather high-level but still related experiments such as my 10x productivity guide with ChatGPT or a process overview for augmented VCs that attracted surprisingly much attention. Reading your diverse feedback DMs and comments (thank you so much!! always helps me to improve my content), I took a step back and tried to understand why these IMO high-level posts resonated so incredibly well whereas some other IMO super valuable deep dives performed comparably bad.
Seeking product-market fit
Assuming that post performance correlates with the value perceived by the readers (ceteris paribus), there must be a disconnect between the depth of the many deep dive posts I shared earlier last year and the level of technical sophistication of most VCs out there. Said differently, the further the distance between the level of sophistication of the reader from the level of sophistication of the content, the less valuable the content becomes and the worse it performs.
An analogy: If a Professor is supposed to learn from a primary school book, she’ll get bored right away. Little value. The same goes the other way around. If a primary school student is supposed to read academic papers, he’ll probably understand very little and at most takes away some inspiration. Again, little value. Both scenarios share that the level of sophistication of the content is too far away from the level of sophistication of the reader.
Yes, this insight seems obvious and is no rocket science but visualizing it helped me to make sense of the varying performance of different content pieces, i.e. my technically less sophisticated posts performed better than technical deep dives. With this rationale in mind, I tried to draw some conclusions about the VC audience and, more specifically, the status quo of the level of technical sophistication of VCs.
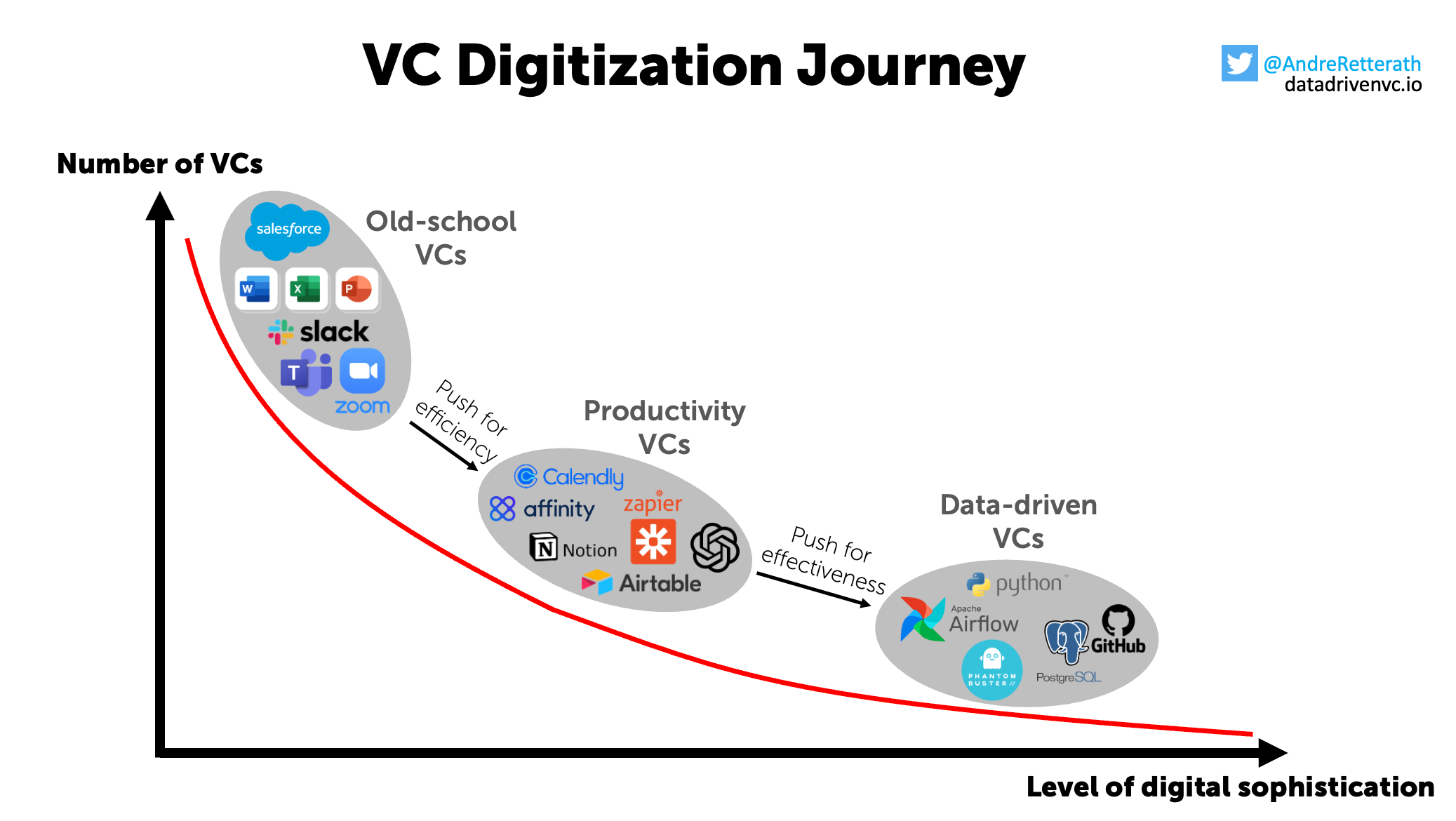
3 stages of the VC digitization journey
The majority of VCs still live in a world with manual workflows, a simple tool stack with a generic CRM system like Salesforce, basic Email and note-taking tools like Apple Mail and Notes, Slack and/or WhatsApp for ad-hoc communication, Teams or Zoom for calls, G-Suite or MS-Suite for document storing and that’s more or less it. This is the “Old-school” extreme on the left side of the figure above where seemingly the majority of VCs are still stuck.
Next, we see the “Productivity VCs” in the middle of the figure above who are either setup with a modern off-the-shelf tool stack from day one or, and this seems to be the majority of VCs, firms that have been pushing for productivity and migrated from the old world. They successfully took the first leap and upgraded their “Old-school” stack with modern VC-focused CRM systems like Affinity or Attio, automated their workflows with Zapier, leveraged Notion for knowledge sharing and are hungry to explore further automation potential via tools such as ChatGPT.
On the right side of the figure above and at the end (?) of the journey, there exist comparably few technically sophisticated “Data-driven VCs” developing their own solutions with scalable web crawlers and proxy servers such as Phantombuster or ScraperAPI, pipeline scheduling tools like Airflow, databases like PostgreSQL or Neo4j, proprietary back- and frontends, and a lot more. While I consider true “Data-driven VCs” as the ones building proprietary solutions and transforming the core of their business in-house, the leap from a “Productivity VC” to a “Data-driven VC” can also be taken via external solutions such as Specter, Harmonic, Gravity, SourceScrub or any other provider out there.
The “Number of VCs” on the y-axis across the three phases above is inversely related to the degree of digital sophistication. This trend seems not only intuitive but has also been confirmed by the data collected as part of the “Data-driven VC Landscape 2023” (stay tuned, crunching the data to publish the report soon). Please honestly participate in the anonymous poll below as it helps me to better calibrate my content.
While my technical deep dive posts are probably most useful to a smaller group of sophisticated “Data-driven VCs” as well as some innovative “Productivity VCs” that are willing to take the next step, the rather high-level posts seem to resonate well with a larger audience of “Old-school” and newbie “Productivity VCs” that are still earlier in their digitization journey.
Mapping my content performance data with the different phases of the VC digitization journey, I couldn’t have framed my conclusion better than my friend Pietro from EQT who commented on my 5k milestone post earlier this week:
Although I started this newsletter with a crystal clear thesis in mind, I had little expectations and clarity in terms of the potential audience. Thankfully, data guides my way and sheds light into the dark 🤓 Hi fellow productivity nerds!
Meeting you where you are
Wondering why I bored you with the above thoughts? Because it led me to think if I should focus more posts on the “Old-school” and “Productivity VCs” who want to become more efficient versus going super deep and narrow on rather techie/nerdy and more sophisticated “Data-driven VCs”. Said differently, I’m considering writing about topics even earlier in the digitization journey to build a bridge and help the “Old-school” and “Productivity VCs” catch up. I’m thinking about hands-on workflow automation guides, productivity tool reviews, Notion templates, prompt databases for ChatGPT and a lot more.
Overall, the content performance data reconfirms one major learning: The transition from an “Old-school VC” to a “Productivity VC” and eventually a “Data-driven VC” is a journey. It’s not binary but takes time and effort. It requires us to zoom out, continuously rethink the “how” behind our business and sharpen the saw to gradually become more efficient, effective and inclusive. As many of you have asked me about my digitization journey at Earlybird, here is our story of transforming a 25-year-old VC firm into a “Data-driven VC”.
Our “digitization journey” at Earlybird
When I joined Earlybird in 2017, our tool stack looked exactly like the one for the “Old-school VCs” above. In 2018, we revamped our website and added a new submission form that created a significant increase in inbound deal flow. This sudden overload forced us to either hire several new team members (=asking for faster horses) or rethink our processes from scratch (=looking for cars). Thankfully, we found Zapier and used it to automate a range of workflows. We started sending an automated confirmation email to the submitter, forwarded and uploaded the submission into our CRM system Salesforce IQ and distributed the investment opportunities to different team members to balance the workload and keep turnover times low.
“If I had asked people what they wanted, they would have said faster horses.” - Henry Ford
In parallel, we faced several shortcomings in our CRM system and started to look for alternative solutions. Unfortunately, the market for VC-focused CRM systems was very immature and we ended up with fewer options than we anticipated. One of them was Affinity, the seemingly best solution offered by a Series A startup in 2018. Felt a bit odd to entrust an early-stage startup with our core data, but we gave them a shot.
Unfortunately, it didn’t take long for the first roadblocker to come up: Migrating our close to 100k entries from Salesforce IQ to Affinity. Batch download or data dumps were not available for Salesforce IQ, so our Affinity customer success POC told us to manually download every profile to then upload it again to Affinity. Wait, that is 100k times 30-40 seconds… so 830+ hours… or 100+ working days..
🤯 WTF? Again, the most obvious next step would’ve been to ask for faster horses (i.e. hire some interns or working students for the migration) but thankfully we had an amazing car in front of our door (i.e. we were investors in the leading robotic process automation (RPA) company UiPath). Their product allowed us to migrate all data within hours. Although Affinity was far from perfect back then, it has been a great decision to make the move earlier than later and grow together with them ever since.

Around the same time, we noticed that storing our deep dives and market research in G-Drive involved too much friction as people rarely accessed these valuable documents thereafter. Some hours of research later we decided to try out Notion. Little to lose. Quickly after onboarding the team, people started creating process trackers, interactive startup landscapes, onboarding guides, insights pages for portfolio companies etc. Wow. Mind-blowing to see so much creativity all around. As a heavy Notion user I can tell: Notion templates are a rabbit hole by itself.
On our quest for productivity, we also tried out a crazily hyped email tool called Superhuman. Many liked it, some did not. When Covid hit in 2020, it suddenly shifted our in-person meetings to Zoom calls. Although we had virtual calls before, Covid was a game changer as litteraly over night all meetings moved from in-person to Zoom. The additional scheduling overhead was just one of the many consequences. Thankfully, we found Calendly and Mixmax for self-serve scheduling. Reflecting on our journey back then, it felt that by mid of 2020 we had done the majority of the heavy lifting to transition from an “Old-school VC” to a “Productivity VC”.
In parallel to this natural transition, I finished my PhD research on “Machine Learning and the Value of Data in VC” and started to experiment and productize the first ideas. While the conceptualization began sometime in 2017, it took me until 2019 to formulate this clear “Data-driven VC” vision and prioritize the different pieces of the stack. On this basis, we hired our first Engineer in 2020 to drive these efforts full-time. The ramp up of our “Data-driven VC” journey seamlessly overlapped with the fade-out of the “Productivity VC” transition. The subsequent part of the journey is also where I dedicated most of my earlier episodes, so feel free to read the details here.
Hopefully, you can find yourself somewhere on this journey (or even ahead?!). We all share the same challenges and hopefully, this newsletter gives some guidance and inspiration. Please participate in the poll above, so that I can tailor future episodes even better to your current phase of the journey and meet you where you are.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Feel your pain on the Salesforce to Affinity migration...!
Surprised if you could really capture (& migrate) all the data in the old system using RPA or whether you had to draw a line somewhere and just compromise in light of the advantages of the new system.
We found the Affinity import interface a little tricky to get everything in as we would have liked
I declared myself as being data-driven and asked for research and deep insights - that said, I am at the very beginning of this road and would not mind reading at any level of depth