

Data-driven VC #19: Value accrual in the modern AI stack
Data-driven VC #19: Value accrual in the modern AI stack
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 4,913, +270 since last week
This post was written by my colleagues
, Laurin Class and me and was originally published on the Earlybird blog. Following your continuous interest in my previous ChatGPT-related posts (“10x your productivity with ChatGPT” and “What ChatGPT means for startup funding”) and the positive feedback on our original Medium post, I am reposting it here for the Data-driven VC community.“There are decades where nothing happens; and there are weeks where decades happen” — Lenin
Over the last few years, one seismic event after another elicited a recitation of Lenin, so much so that at some stage it felt like screaming into the void, most of us desensitized.
Scientific breakthroughs, though, still have the power to grip us like nothing else. The sheer euphoria with which people are reacting to the latest advances in transformer-based large language models is deafening. Most of the commentary is incredulous at the colossal steps AI has taken this year.



It’s hard to resist the feeling that we’re in the early innings of a profound technology shift, with a starry eye toward the horizon of what’s possible in the future.

In a relatively short span of time, investors have already amassed volumes of analysis on the antecedents to AI’s current moment. Top of mind for investors, though, is the question of capital allocation: Which components of the AI ‘value chain’ are most attractive for VCs?
With a market that’s evolving at such a ferocious pace, any conclusions will rest on a bedrock of assumptions. Despite the incredibly captivating power of models today, we’re still in the early innings of the revolution. What we can do is simulate different moves on the chessboard and assign probabilities to each outcome, which ought to give us some foresight into the winners in the AI value chain.
The State Of Play
Research into machines that are capable of emulating human intelligence dates back to the 1950s. Many Gartner hype cycles followed and faded, but research kept ticking along, compounding, with each subsequent breakthrough building on top of the corpus of predecessors.
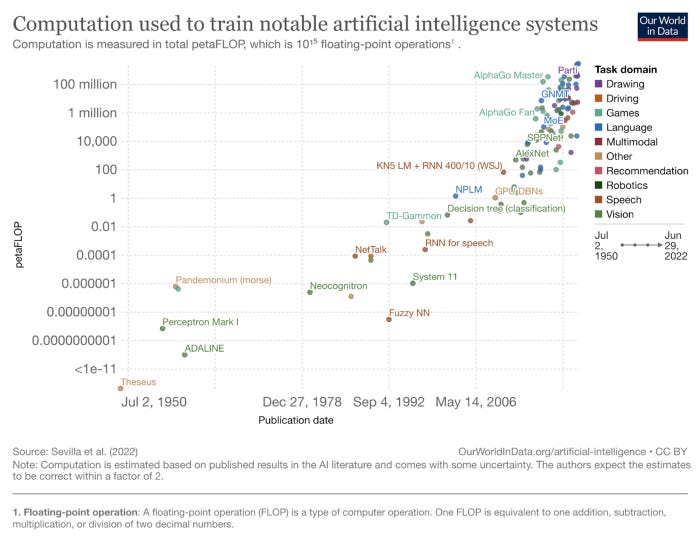
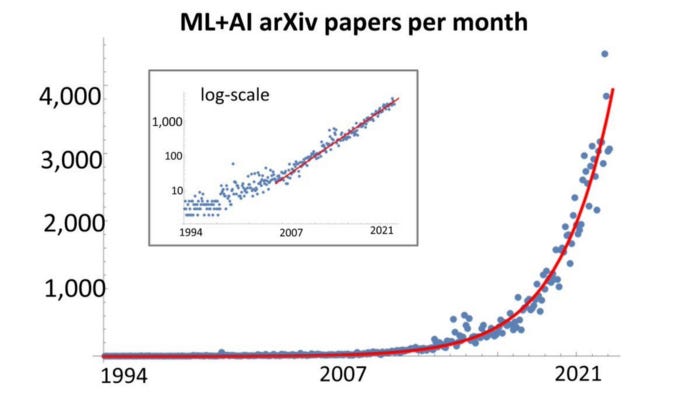
Through these cycles, there was a gradual shift from scholarly publications and academia to private investment from commercially oriented organizations. The preceding decade saw the formation of several research labs from both incumbents (e.g. Google, Meta) and startups (e.g. OpenAI), each mobilizing vast compute and data resources to advancing ML; the inflection in research papers that followed is clear to see.
Two milestones account for much of the inflection that coincided with the emergence of the research labs. The first was in 2012, when Alex Krizhevsky of the University of Toronto demonstrated the superiority of deep learning neural networks over state-of-the-art image recognition software, having trained the model on GPUs that were capable of handling trillions of math operations. From this point onwards, ML models had the computational capacity to scale, leveraging the advantageous properties of GPUs such as parallelism to perform compute-intensive tasks like matrix multiplication that are at the core of AI models. GPUs are leaps ahead of others ASICs like Google’s TPUs in terms of market share (within GPUs, Nvidia has the lion’s share of the market, but more on that later), despite TPUs being better for the training of many models. In short, GPUs unlocked a new paradigm of computing capacity.
The second catalyst was the publication of a landmark paper in 2017 by a team of researchers from Google. The paper outlined a new architecture for deep learning models that relied on attention mechanisms in a novel way, eschewing previous methods (recurrent networks) to deliver superior performance. Transformer-based models lend themselves to parallelism and are therefore able to derive maximum value from GPUs, requiring less time to train. These two seminal developments culminated in Transformer-based ML models flourishing ever since, incurring significantly more compute to scale.
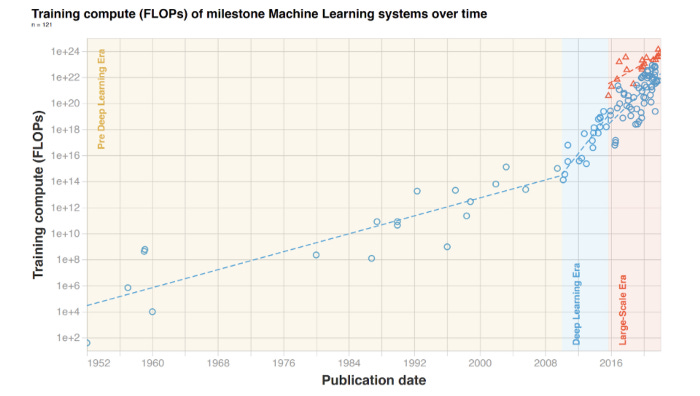
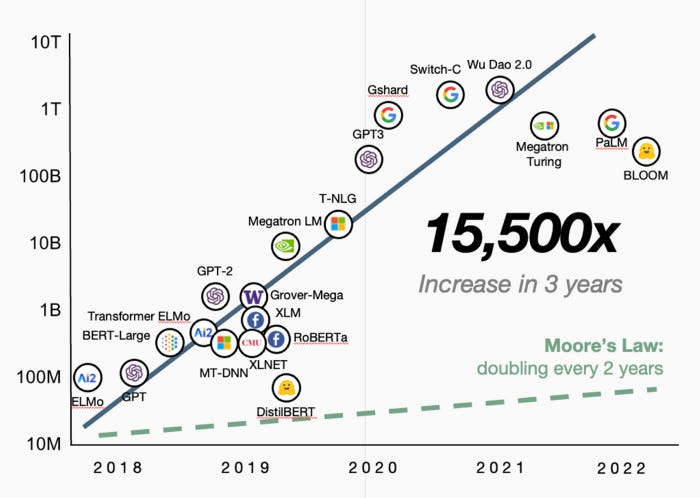
Notably, although the initial applications of Transformers were focusing on Natural Language Processing, recent academic papers on transformers give ample evidence of how transformative (excuse the pun) this architecture is across different modalities beyond text generation.
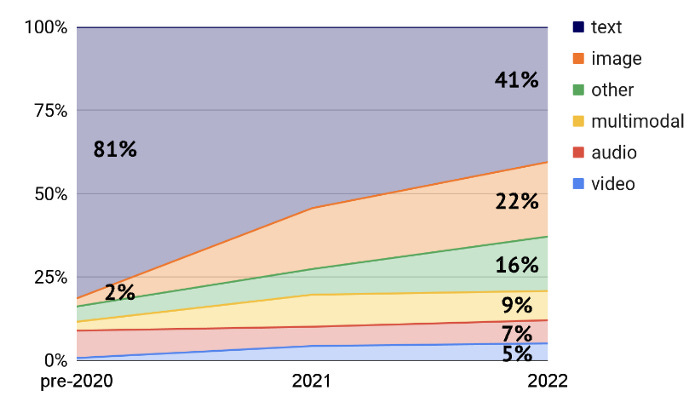
When we extrapolate the post-Transformer trajectory of model performance into the future (without allowing for further breakthroughs in compute or model architectures), it’s no wonder that AI is being heralded as the next platform shift after personal computing, mobile, and the cloud.
Our perception of technological advancement is often too linear, extrapolating based on past growth rates, preventing us from grokking exponential change when it’s before us.
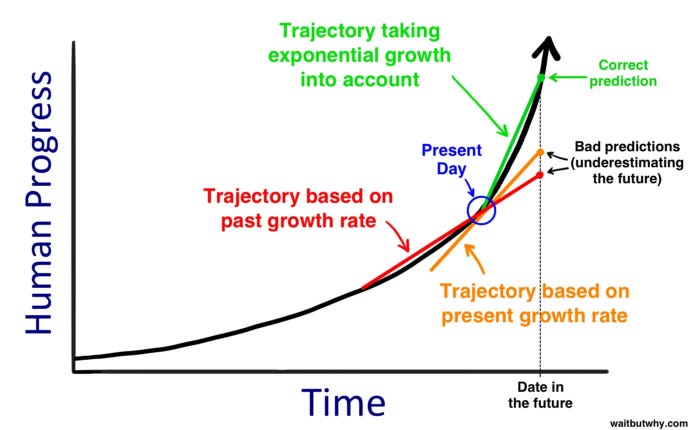
That naturally leads us to underestimate the range of future outcomes, diluting the truly plausible and preposterous future scenarios for AI’s development and its impact on humanity.

Weighing these outcomes against probabilities directly translates to investment theses on how the AI value chain will evolve, where the long-term value capture will be, and commensurately where the biggest companies will be built.
Infinite Possibilities
The AI vendor landscape does not neatly conform to a value-chain framing, because all of the components bleed into each other to varying degrees — a dynamic that’s only likely to further accentuate over time.
That said, this framing from Evan Armstrong covers the general contours of the technologies behind today’s applications:
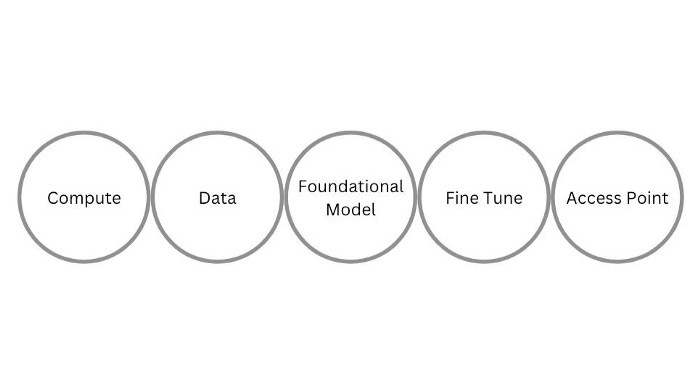
Compute powers the foundational model research companies that train their models on huge volumes of data, to deliver a pre-trained transformer model to the builders of applications. These application builders may elect to fine tune the model with domain specific data to derive superior performance for specific applications that serve as access points to AI for the general population.
To begin answering the question of long-term value capture, we first have to determine the conditions in which these companies will be operating. One of the most important variables that will dictate any specific company’s propensity to venture upstream or downstream of itself in the value chain is Total Addressable Market (TAM). The framing we can use to think about this is:
The total value creation attributable to AI is large enough to accommodate X categories (infrastructure & application-level) and that each produces X billion in revenue
If the total value creation is insufficient to support a multitude of categories, which component of the value chain is best equipped to move upstream or downstream to capture more value
Let’s take the analogy of data infrastructure. The shift from on-prem to cloud spawned numerous categories oriented around getting data into production and deriving value.
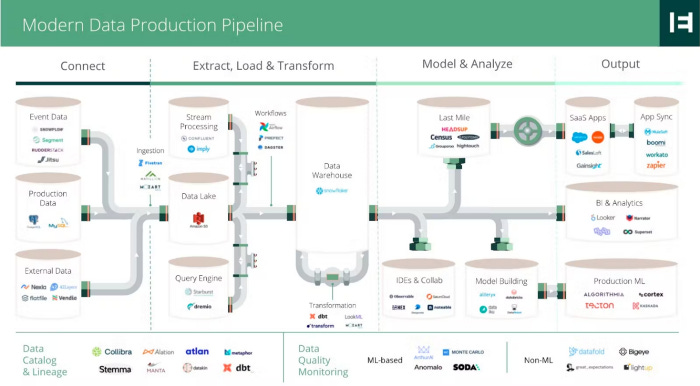
The secular trend was powerful enough to produce many billions of dollars in enterprise value, which has managed to endure downturns more resiliently than other software categories — most of the fastest-growing software companies are cloud infrastructure companies, accruing the highest multiples.
You could argue that some of these categories ought to be subsumed by larger, more defensible layers of the stack (and many are attempting to). That may well happen in the future, but the bigger principle is that the total value creation from data was abundant enough to support the formation of several categories at the infrastructure level. Each category and its winners were largely content to focus on their core value proposition without others breathing down their necks because of a capped market size.
To further illustrate this point, we can juxtapose data infrastructure with fintech infrastructure, specifically Open Banking. Open Banking’s promise was to break down the walls erected by banks to precious customer banking data, unlocking many applications like personalized financial management tools, credit scoring and decisioning, and account-to-account payments. Infrastructure players emerged to provide access to bank account data via clean APIs, most notably Plaid in the US and TrueLayer in Europe. Despite the perceived promise of open banking, adoption growth has been much slower than fintech practitioners expected, which forced many infrastructure providers to cannibalize their customers by moving upstream into applications, most notably payments.
Precise market size calculations for AI are superfluous, but a sense for the magnitude gives us an indication of the competitive dynamics that are likely to unfold over time. A qualitative approach would be to gauge the latent market for generative AI applications. Generative transformer models have brought the cost of content creation down to zero, just as the internet brought the marginal cost of distribution down to zero. It’s not a massive stretch to argue for a future where AI-enabled products act as a market-creating innovation that will enable existing SaaS and consumer applications to drive both TAM penetration and expansion (more radical outcomes like Artificial Superintelligence or digital lifeforms are well beyond the scope of this post).
There are several proxies of this latent demand. Take ChatGPT, an interface for GPT 3.5, which ascended to 1 million users faster than some of the most well-known consumer tech companies in history (OpenAI, one of the largest closed-source foundational model companies, is purportedly pitching $1 billion of revenue in 2024 and contemplating whether to monetize ChatGPT).
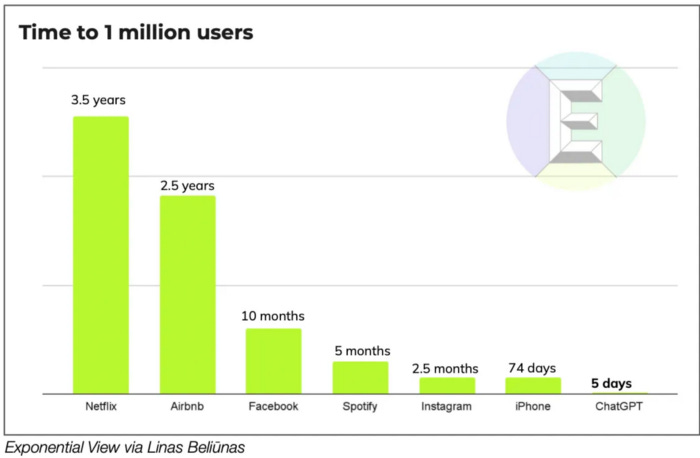
Or take HuggingFace, an open-source library of pre-trained transformers that developers can fine-tune for different applications in production (e.g., text classification & generation) — it’s one of the fastest-growing open-source projects in history.
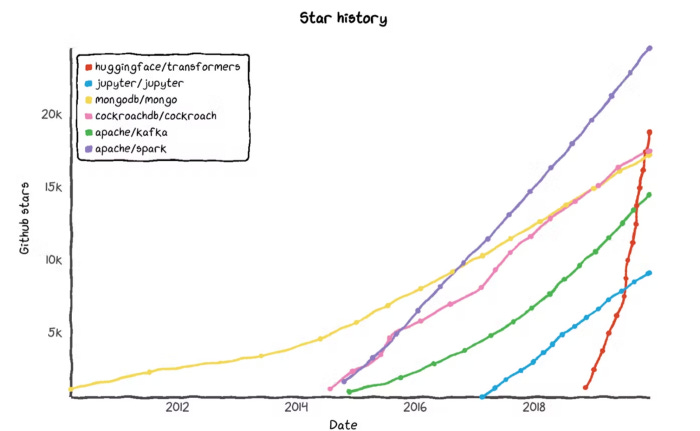
We’re still in the early innings, but the early evidence affirms the view that AI truly represents a platform shift of a similar magnitude to mobile and the cloud, and that a universe of applications will emerge on this new platform.
It’s no surprise, then, that the AI value chain is often likened to cloud infrastructure.

The comparison is intuitive: a concentration of large companies expending a significant % of revenue on capex to power vital infrastructure that enables applications to be delivered in a faster, cheaper and more scalable manner. The infrastructure providers (AWS, GCP, Azure) became hyperscalers by simply focusing on what they do best, letting applications deliver value to the end customer.
The value created by AI is likely to be enough to sustain many billions of dollars in enterprise value creation. It’s the quality of the underlying revenue that’s more contentious.
Applications building on top of APIs from the foundational model companies have ostensibly no barriers to entry. How defensible are their margins and how good can retention ever get? Conversely, will the foundational models become commodities with little to no switching costs for the applications consuming their APIs? Or will there be a capital arms race between an oligopoly of closed research companies, who are able to extract maximum value from the stack? Finally, will AI ever be truly open source, or will closed companies develop a yawning gap that their open-source counterparts will never be able to bridge?
The chessboard is finely poised.
The right to win
As we’ve discussed, the antecedents for today’s revolution are building blocks stacked on top of each other — GPUs proving capable of handling the computing load that AI models require, foundational model companies leveraging a transformer architecture, and finally applications leveraging these newer models, either via API or deploying open source transformers. This chain implies a certain level of dependency on the extant blocks that came before.
Let’s begin by examining the compute layer. Nvidia’s GPUs are leaps ahead of competitors, including both incumbent competition from Google and from startups like Cerebras, Graphcore, Groq, and SambaNova. We’re already familiar with the roughly equal market distribution between the cloud hyperscalers AWS/GCP/Azure that host the foundational models. Together with Nvidia, the main actors at the compute layer are the cloud hyperscalers, all of whom have been investing heavily to maintain their positions.

We can see how the cloud hyperscalers have either invested directly or partnered with foundational model companies. Although Nvidia hasn’t gone down this business development path, it has been investing heavily in AI research and continues to win recognition for their cutting-edge contributions — a new generation of H100 GPUs is on the horizon, to supplement the already dominant V100 and A100 chips.
There is a healthy symbiosis between the compute and foundational model layers. If we take ChatGPT, which has 175 billion parameters, back of the envelope math would suggest that OpenAI is paying Microsoft c. $100k per day for the cost of the requisite 8-GPU server. Innovation at the silicon layer of the hardware requires ‘an emphasis on software and interconnects’ (the likeliest challengers to Nvidia’s position are the cloud hyperscalers themselves). Innovation in foundational model research requires access to larger datasets, further iteration on transformer model architectures, and training approaches. These are very distinct, diverging lanes.
The majority of the capex and R&D in the AI value chain, however, lies at these two layers, which explains the marriages we’re seeing. The dynamic between the compute and foundational model layer is likely to remain collaborative rather than competitive.
The raison d'être of foundational model research companies is producing more powerful models, but there’s a fission between closed-source and open-source approaches at the research level. In a perfectly efficient market, would capital be disproportionately allocated towards closed companies that are better able to capture value, thus preventing open-source competitors from maintaining model parity? It’s a very plausible scenario, and one which would run against the recent history of open-sourcing of large models in short timeframes.
This tees up the question of whether most production use cases (applications) of AI will deploy open-source models (e.g. via Huggingface) or call the API of closed companies. The eventual distribution is one of the most important variables to our question of long-term value accrual — we can best observe this by juxtaposing the likely value capture in scenarios where OpenAI (closed-source) or Stability (open-source) accrue significant market share.
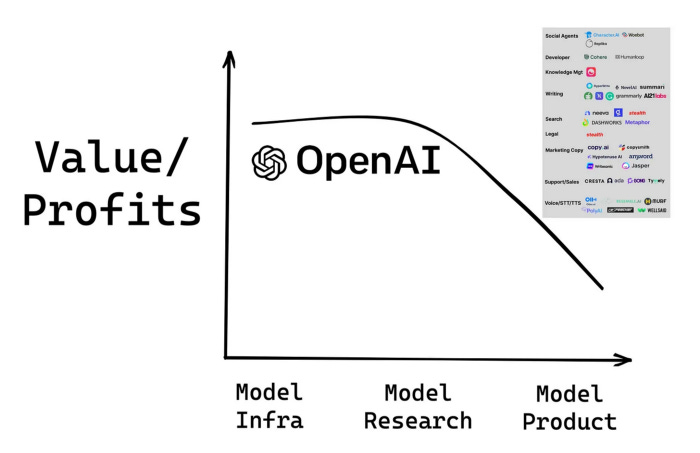
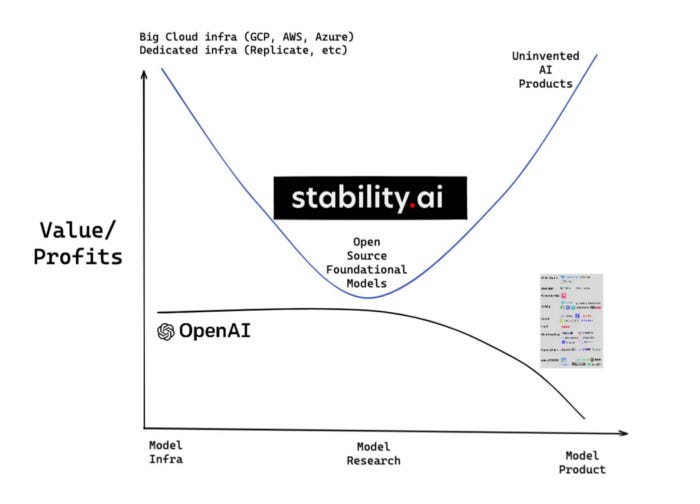
We can clearly see how Stability’s stated aim to remain a non-economic actor redistributes value to applications, whereas in a world of ubiquitous OpenAI models the applications capture a fraction of the value generated.
If we keep to the analogy of foundational model research companies following the trajectory of the cloud hyperscalers (and the eventual market distribution), the next few years will see consolidation to just a handful of players. One plausible scenario is the one we’ve raised already of closed-source companies pulling away from open source competitors (aided by capital and talent flywheels), producing a perpetual delta in model performance over open source competitors.
Most applications would be left with a stark choice of taking inferior open source models and fine-tuning them to narrow the gap for their domain, or simply accepting the superiority of the closed-source APIs and acquiescing to the pricing.
Now that we’ve already made a few suppositions about the evolution of the value chain, let’s follow these developments through to the next logical step and discuss the application or endpoint layer, and how it’s likely to fare.
Companies building at the application layer are the companies that are best placed to truly democratize access to AI for the masses — an illustrative example is Jasper for marketers. Jasper has abstracted away the GPT-3 API into a UI that makes the model’s power accessible to copywriters. Many have covered the levers responsible for Jasper’s phenomenal growth, having reached 70,000 users and generating $75m in revenue within 18 months of launch, up there with the fastest-growing SaaS companies in history.
A few of the drivers behind Jasper’s success in productising GPT-3 are: integrations tailored to use cases for copywriters, fostering a thriving community that shares best practices and templates, nailing onboarding to maximize Time To Value, and adopting a headless approach to smoothen distribution. Jasper’ CEO sums up the guiding philosophy of application layer companies best:

The AI Grant program, funded by Nat Friedman (ex-CEO of Github) and Daniel Gross (formerly ran ML projects at Apple, started YC’s AI program), has perhaps the crispest articulation:
Some people think that the model is the product. It is not. It is an enabling technology that allows new products to be built. The breakthrough products will be AI-native, built on these models from day one, by entrepreneurs who understand both what the models can do, and what people actually want to use.
The universe of applications is vast and extends across generative modalities (e.g. video, image, code) and use cases (e.g. copywriters, video editing). As many of these applications reach scale, the specter of foundational models moving upstream looms large. As the foundational model layer consolidates, what are the barriers to them capturing the product-level value? There’s an argument to be made that ChatGPT already obviates Jasper’s core product to some extent. It’s plausible that the hypergrowth of the applications is masking leaky retention. Jasper’s margins are estimated at 60%, but this is certainly on the upper end for application layer companies.
On the chessboard, the foundational model and application layers are the most likely to become adversarial when it comes to value capture in the very long-run (even though the TAM attributable to AI is likely to sustain a healthy symbiosis in the interim). Foundational model companies, having expended such significant capex to improve their models, would argue they are better positioned to move upstream than the applications in-sourcing the models and reaching anywhere near performance-parity.
Several application layer companies have already attempted to own their models. RunwayML brought attention to their positioning as a full stack AI company in their most recent funding round (the co-founder of RunwayML was a key contributor to Stability.ai’s models) and Descript acquired Lyrebird to become their AI research division, starting with their Text-to-Speech product, Overdub.
Conversely, there are also existing examples of foundational model research companies providing the tooling to implement their models - take Aleph Alpha*. Aleph Alpha is building a European alternative to OpenAI, hosting its models on the most powerful commercial AI data center in Europe and focusing on European languages (among English of course) — the security advantages are imperative to sensitive verticals like governments. Aleph Alpha also leverages more efficient training approaches to achieve state-of-the-art performance with less than 50% of the model size. Most importantly, Aleph Alpha provides tooling on top of their foundation models that support the delivery of their models. In doing so, Aleph Alpha provides a full-stack product with a top-down enterprise sales approach.
Going full-stack from either approach has one major barrier: talent.
It’s not ML talent that’s the bottleneck — the trend for Computer Science majors concentrating on AI is encouraging.

The talent bottleneck is at the intersection of research and product.
‘It will take creative people new cleverness to build successfully around ML, and the overlap between great product people and those who understand ML is today small’
Building consumer-grade SaaS applications to productise AI requires a different talent pool to the one that’s pushing the frontiers at the foundational model level, as Elad Gil noted:
As we move from the era of only big models to the era of more engineering and applications, the other shift in the market segment will be from PhDs and scientists to product, UI, sales, and app builders. Expect an influx of product/app/UI-centric founders into this area in the coming years.
Winning teams at the foundational model and application layers are fundamentally different. Foundational model companies excel by hiring the best ML researchers, whereas application layer companies are best placed to become platforms/systems of record by recruiting the best product and execution talent.
There’s one more element to the battle between the foundational model and application layer: incumbents. The most favorable simulation of the future for applications is one where the models become commoditized (possible but unlikely if we assume capital is concentrated around a few closed-source companies) and applications have no switching costs between different model providers. If we follow this line of thinking through, then the question that immediately springs to mind is: won’t the incumbent SaaS companies bundle AI into their product set?
For instance, Copy.ai is hoping to rely on its AI-assisted copywriting tool as a wedge into companies, eventually integrating into their customers’ existing software stacks to automate growth marketing, possibly supplanting Hubspot. A similar playbook is at work for most applications, using AI as a wedge to eventually build a platform or system of record (assuming AI is commoditised). In such a scenario, AI-native applications won’t be insulated from the threat of incumbent tools like Notion, Figma, Hubspot, and Slack, who already have the distribution, from integrating AI into their product set.
There are a few plausible vectors of defensibility for applications, like verticalization and accompanying workflows, fine-tuning of models proprietary data (either usage or private data collected by a network, e.g. healthcare), and community/GTM. Even so, with threats from the model layer and from incumbent SaaS companies, the path for AI-native application companies to scale and achieve healthy margins, unit economics, and retention is the most fraught with threats.
Final words
We’re witnessing a platform shift that will have wide-reaching implications for knowledge workers and the global economy. There are too many moving parts to have a firm grasp of how the technology, and its value chain, will evolve. We can only present plausible future scenarios and interpolate likely winners in the value chain based on different simulations.
Mental pliability is paramount. At Earlybird, we look to test our assumptions at every opportunity.
To that end, we look forward to healthy debate and discussion with founders, investors and other contributors to the AI ecosystem in Europe.
*Aleph Alpha is an Earlybird portfolio company
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Fantastic and inspiring! Thanks! 🦾