

Data-driven VC #17: 10x your productivity with ChatGPT
Data-driven VC #17: 10x your productivity with ChatGPT
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 4,060, +629 since last week
Happy New Year 💥 I hope you had some restful days with your loved ones and a great start into 2023. I personally spent most time reading, reflecting and playing around with ChatGPT to make my life easier in 2023 and beyond🤓

VC x AI - A great combo
As most of you know, I spent the last decade as an operator, researcher and investor in the field of AI and continue to be incredibly excited about the (horizontal) technology itself (some related posts “Deconstructing the AI Landscape” from early 2020 or more recently “Value accrual in der modern AI stack”) but also its potential to solve specific (vertical) use cases. This is also how I got to “Data-driven VC” in the first place: Combining my interests in AI (and automation) and VC to make our industry more efficient, effective and inclusive.
Previous episodes of this newsletter were mostly problem-oriented, i.e. where is most value created and what’s wrong with the status quo. For example, 2/3 of the VC value is created in sourcing and screening, but sourcing is inefficient and screening is biased, ineffective and non-inclusive, as described in episode#1 “Why VC is broken and where to start fixing it”. To solve these specific issues, I explored a variety of software techniques/tools (such as web crawlers/scrapers in episode#4, de-duplication/entity matching in episode#5, feature engineering in episode#6 or social network analysis in episode#15, to name a few).
Said differently, until now I mostly identified problems across the VC value chain (nails) and looked for the right tools to solve them (hammer). This episode is different, it’s actually the other way around.

I got a sledgehammer. Where are the nails?
I’ve been closely following the evolution of transformers and large language models (LLMs) since the groundbreaking “attention is all you need” paper in Dec 2017. We’ve seen models like BERT applied across multiple use cases, but widespread adoption has lacked significantly behind its potential. Same with GPT-3. It attracted great (media) attention after its launch in June 2020, but widespread adoption has lacked behind too.
It was the launch of ChatGPT end of November 2022 that changed the game. OpenAI onboarded more than 1 million users in less than five days. The fastest product roll-out ever. But what was different? In my eyes, it’s the introduction of a simple and intuitive UI that in turn reduced the entry barriers for non-technical users. Everyone can use ChatGPT and, as a result, knowledge workers all across have started to play around and solve their specific use cases. So did I for my daily tasks as a VC.
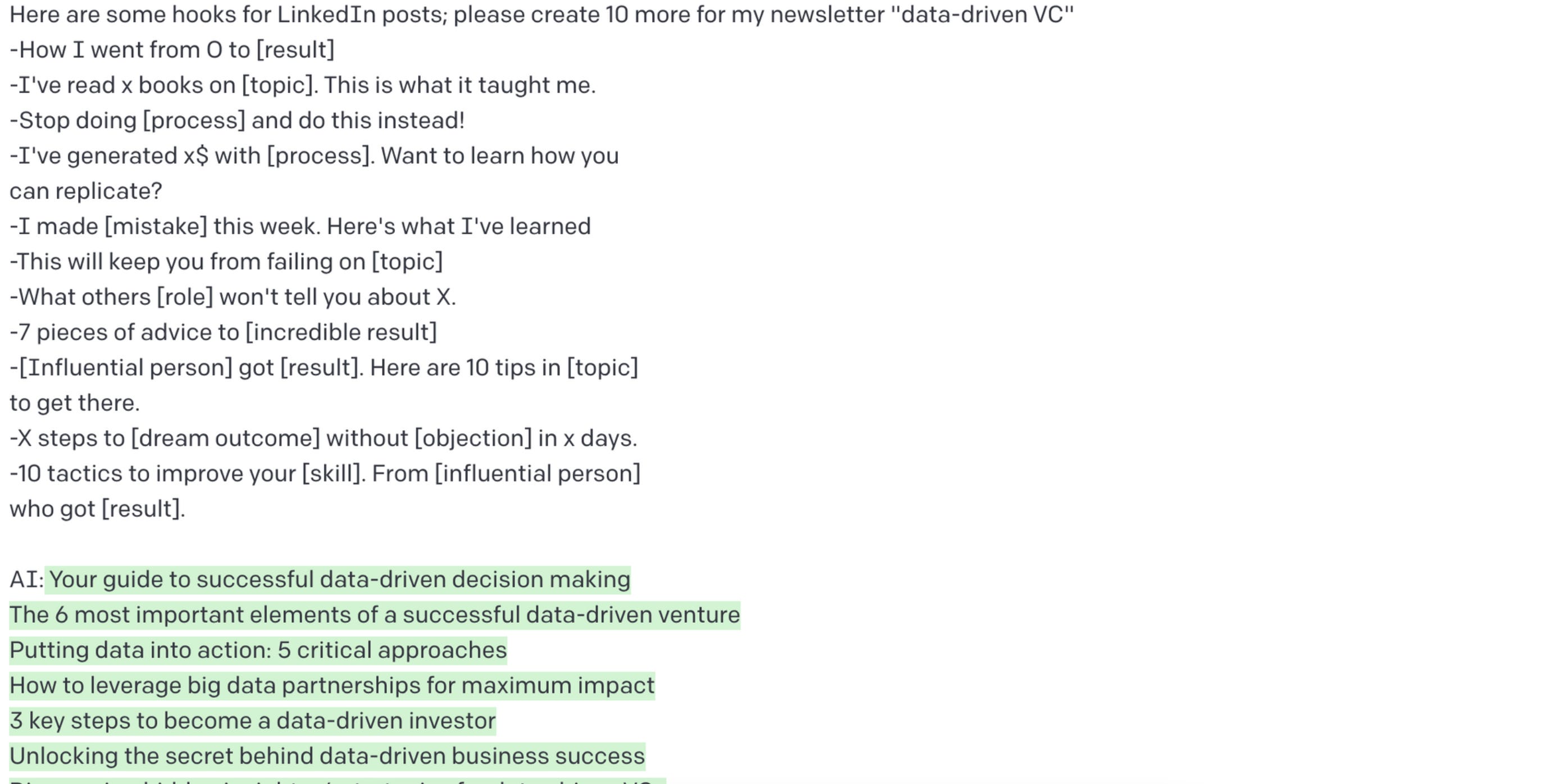
1. Map your daily workflows
In early December, I started collecting different “nails”, i.e. I created a list with every single task that came up and added at least one example of the manual status quo. For better prioritization (which “nail” to start with), I added two dimensions: time per task execution and frequency of this task per week. Multiplying them, we get the total time spent per task per week, or said differently the “automation potential”.

2. Trial & error manual examples in ChatGPT
The OpenAI signup literally takes less than a minute. As a note of caution, I want to mention that whatever you insert as a prompt (=instruction for ChatGPT) will go straight to the servers of OpenAI for inferencing (=processing by a pre-trained model such as “text-davinci-003” which is the latest version of GPT-3.5), so be cautious with sensitive information.
Based on my sorted VC task list above, I started to copy & paste the manual examples into ChatGPT and iterated the prompts multiple times until the answers eventually met my expectations. Below you can find some detailed examples (prompts at the top and the response of the AI highlighted in green below) that you can easily copy and adjust to your needs.
(Website) data extraction into a pre-defined format

Industry classification based on pre-defined tags

Technology classification based on pre-defined tags

Find similar companies/competitors

Measure the similarity between companies/competitors

All of the above examples work with specific company names as long as the respective name is unique. As soon as other companies with the same or similar names exist, I suggest replacing the name with the company URL for more specificity.
Find experts for a specific domain

Determine the sentiment of a media article/post/etc.


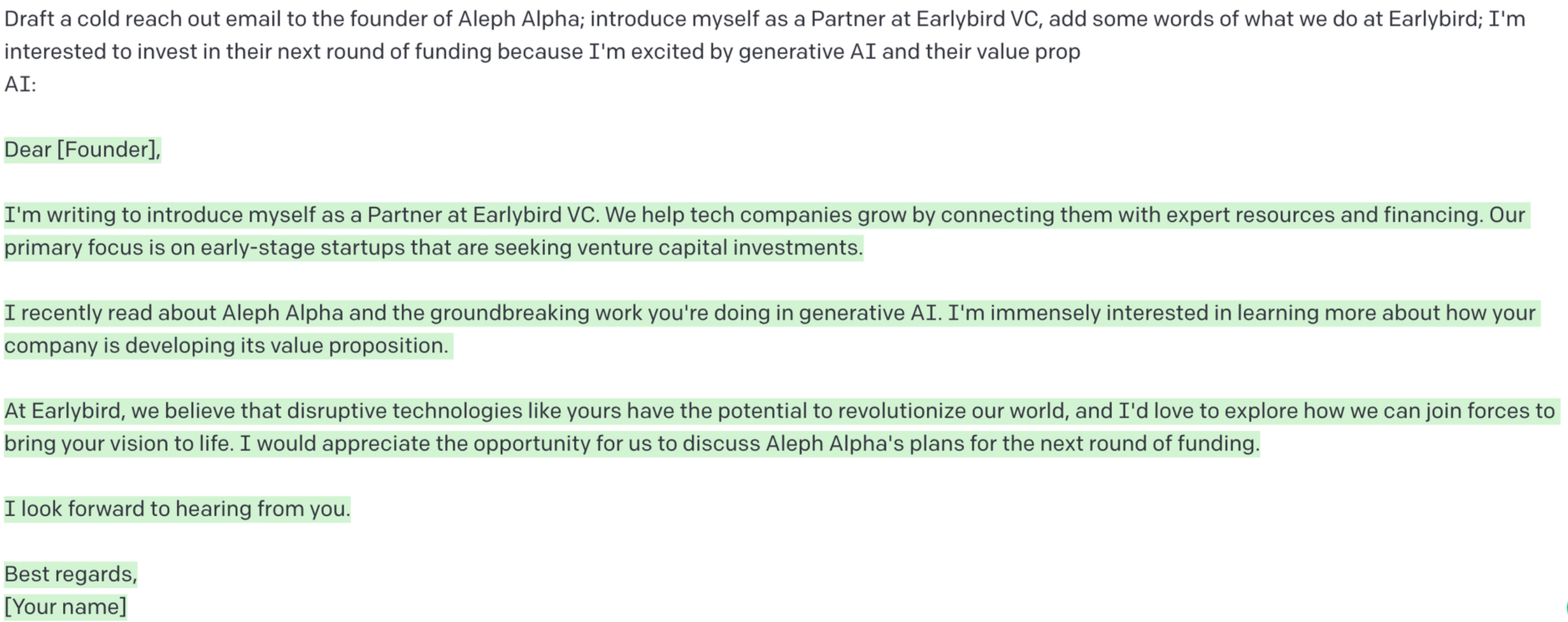
Cold reach-out email
Rejection email

Content creation

Content distribution
What other tasks would you automate? Leave a comment below and we’ll get it done.
3. Automate and scale your workflows via the API
While the ChatGPT interface is sufficient for prompt exploration (this is also why it’s called “Playground”), we need the API to connect the pre-trained models with other applications and scale our workflows. Follow the steps below to get your OpenAI API key.
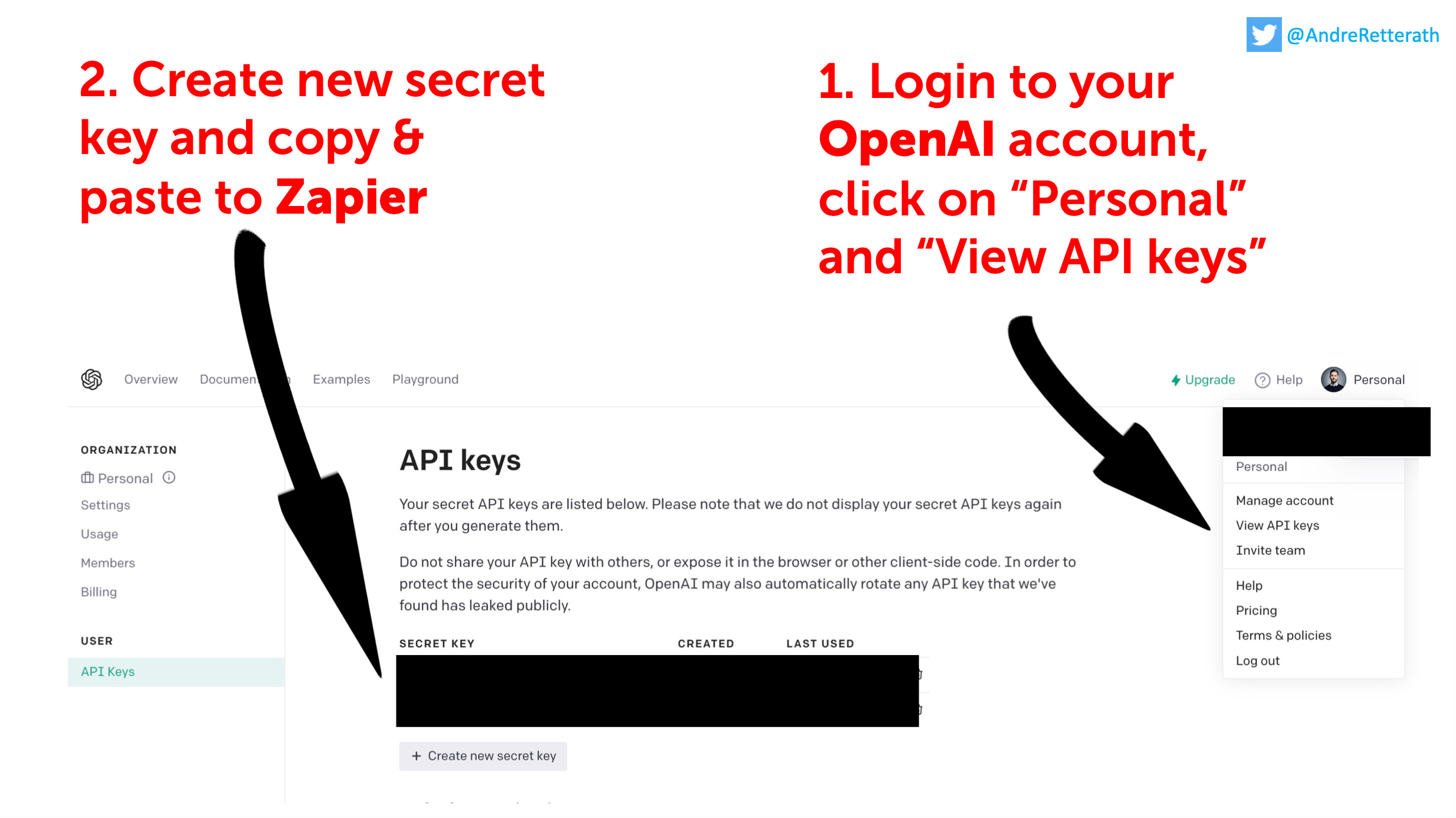
For the less technical readers among us, an API is an Application Programming Interface that allows us to connect two applications which each other. Unfortunately, APIs are often not standardized and it requires manual coding effort to connect them. Thankfully, a range of “intermediary” automation tools evolved to build these connectors once and make them available to everyone.
My favorite solution for many years is Zapier, a low-code automation tool that is super easy to handle and provides connectors to literally every software product you can think of. Just sign up, log in and follow my step-by-step guide in the PDF below to build your first Slack bot and scale all of the above-mentioned workflows.

Besides Slack, you can also integrate OpenAI into other products such as Google Sheets, as shared in my LinkedIn post here. Creativity has (almost) no limits.
In addition to the connection between different tools, we can also use the API to connect it to a proprietary database and hereby extend the “knowledge” of the pre-trained OpenAI models. Wondering why we should do this? For example, the “text-davinci-002” GPT-3 model from January 2022 got trained on a dataset that was collected up until June 2021. By now, it’s likely outdated and would become increasingly useless for applications that require up-to-date information. By connecting the OpenAI API with our database, however, we can leverage the “brain power” of their models on a combined database, including publicly available information until the date the model got trained as well as our proprietary data.
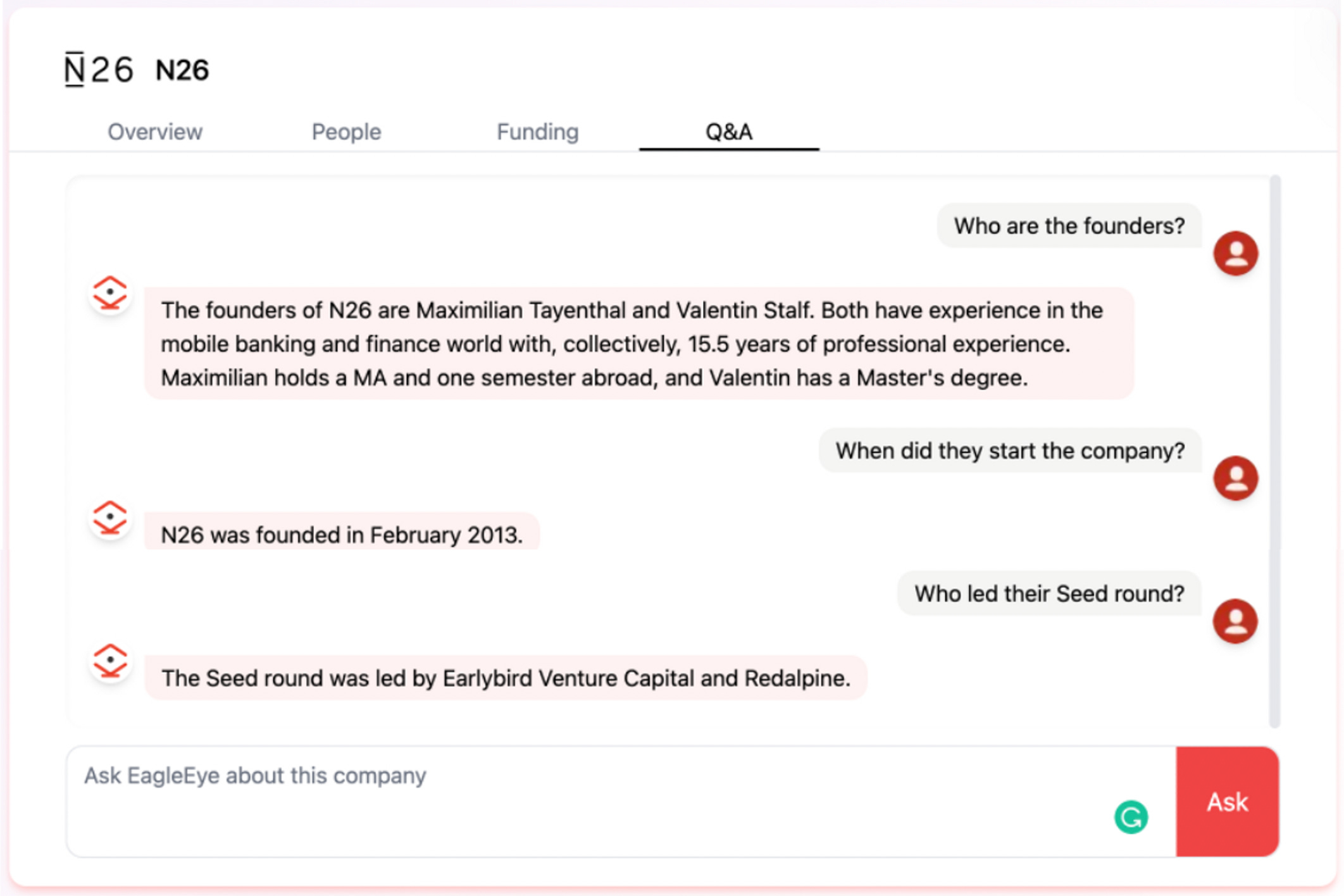
Below is an example of a LLM powered chatbot that we integrated into our internal platform “EagleEye” at Earlybird. By connecting the APIs, we enrich the pre-trained models with our proprietary data and allow the investment team members to naturally interact with the combined dataset via the chatbot, just like with a human assistant. We collect the manually submitted prompts in the back and use them to finetune future prompts and improve the results. This functionality is a great addition to our existing CRM functionalities.
Last but not least, I suggest checking out Aleph Alpha, an incredible company providing similar solutions to OpenAI but with a focus on European Languages (besides English of course) and enterprise use cases, fully trained and hosted in Europe. We at Earlybird were lucky to lead their Series A financing round in June 2021 and are super excited to see the leading European generative AI provider evolve.
In summary, the implementation of ChatGPT, GPT-3 and other LLMs is simpler than you think and allows you to at least 10x your productivity in minutes. Hopefully, this post provides valuable inspiration and guidance for you to automate your workflows and become more efficient in 2023 and beyond! Feel free to share it with others who could benefit.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎
Wow, amazing to read this just as we discovered the same capabilities, Andre. We quickly went from ChatGPT to signing up for access to DaVinci. The next step for our platform for researching 3,232 cybersecurity vendors always included ingesting all their products by name and function. But it took 4,000 hours of my time over years to find and categorize those vendors. Categorizing 10,000 products presented an insurmountable task unless I could afford to hire five experienced industry analysts who were willing to take on a mind-numbing task.
We are ingesting 6,500 products right now, derived from careful queries to DaVinci 3.5, fed with json summaries of the current websites of each vendor. (cost=$450) We get all the products and a feature list for each one. This is game changing. We already have a source of new products, also from an AI trained by Feedly, so keeping current is going to be straightforward.
Dear Andre, thank you for the insightful post! I have a question: How do you go about the margin of error that CHAT GPT still has? I noticed that when researching for the founding year of companies, the answers were sometimes incorrect so we needed to double check all answers which created an equally large amount of work. Are there any fixes to this? Thanks and all the best from Vallendar!