

Data-driven VC #10: Processes and frameworks for augmented VCs
Data-driven VC #10: Processes and frameworks for augmented VCs
Where venture capital and data intersect. Every week.

👋 Hi, I’m Andre and welcome to my weekly newsletter, Data-driven VC. Every Thursday I cover hands-on insights into data-driven innovation in venture capital and connect the dots between the latest research, reviews of novel tools and datasets, deep dives into various VC tech stacks, interviews with experts and the implications for all stakeholders. Follow along to understand how data-driven approaches change the game, why it matters, and what it means for you.
Current subscribers: 2,682, +143 since last week
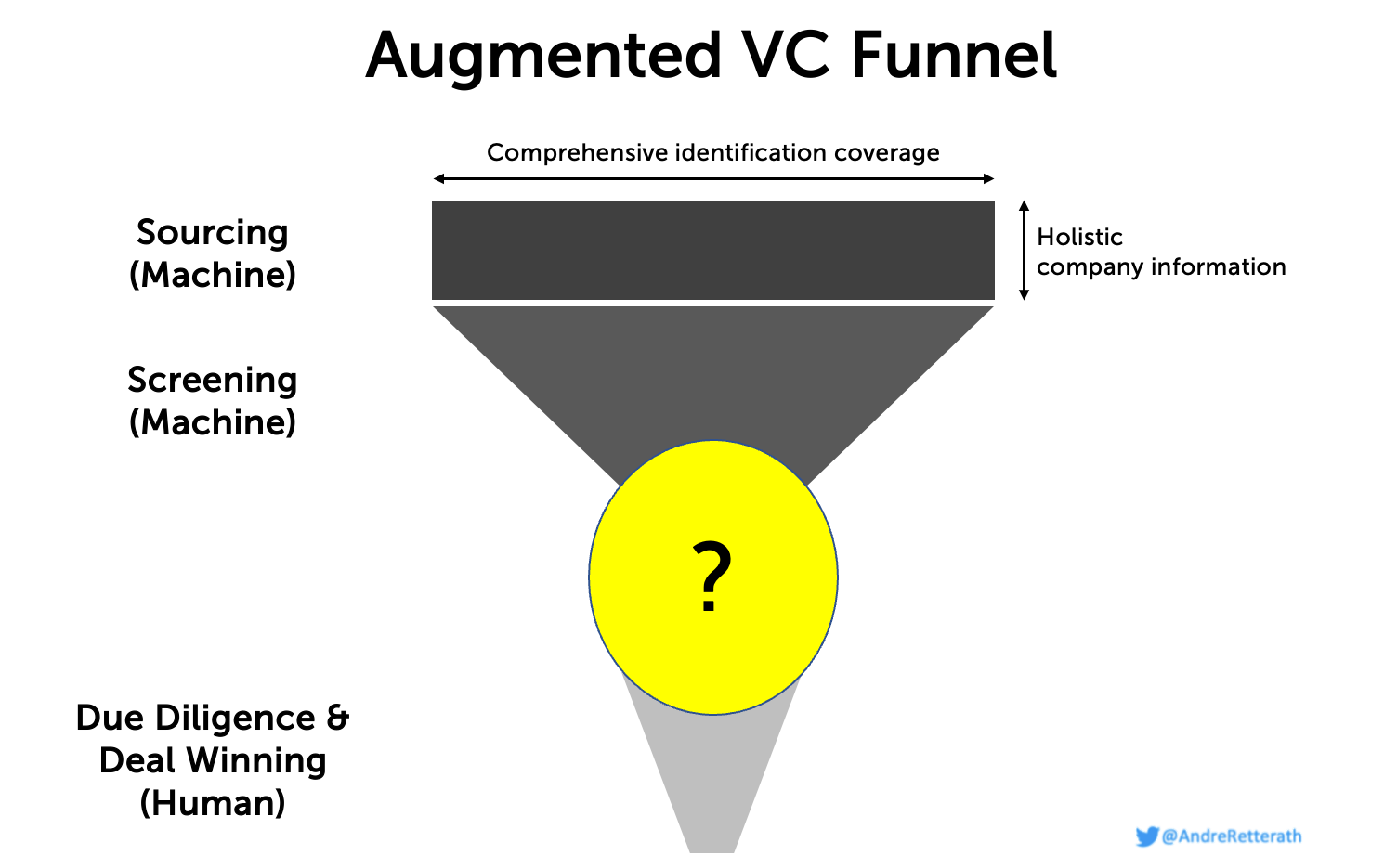
Let machines do what machines can do best, and humans do what humans can do best. Collecting and processing data, and interacting with other humans, respectively. What does that mean in practice? Well, I believe in a future VC setup where web crawlers/scrapers collect identification and enrichment data to achieve comprehensive startup coverage and holistic, well-balanced information about the respective companies top of the funnel but where humans eventually sit together and decide to partner up at the bottom of the funnel. But what happens in-between?
VC use cases: Exploration versus Research
Assuming comprehensive company and data coverage at the top, the next question is how to leverage this information most effectively to narrow down the funnel. In line with the previous identification and enrichment logic, there exist two major use cases that need to be considered for data presentation:
Exploration. Identification of new, promising investment opportunities. Investors need effective and inclusive filters to cut through the noise. I covered this use case in detail in the previous episodes “How to automate startup screening” and “Patterns of successful startups”
Research. Track and follow previously identified opportunities over time or search for specific companies/markets/trends to conduct a deep dive. Investors need a well-organized overview of all existing data as well as the ability to conduct analyses at the point. This has been solved by CRM providers and mainly requires some great UI/UX work, so I won’t go into detail here.
Ultimately, we need to unite both use cases in one interface to create a single source of truth and remove the need for context switching. Exploration is a screening challenge, Research is a UI/UX challenge. To solve the screening challenge, I strongly believe in a hybrid screening setup that combines static, deterministic filters (what the investors look at) with dynamic, ML-based filters (what the data tells us); see my previous episode here.
Benefits of a hybrid screening approach
Static, deterministic screening:
Incorporate your own “style” to differentiate. Assuming every VC uses exactly the same data to identify patterns of successful companies, everyone would end up with the same set of screening filters. In order to differentiate, VCs can easily balance filters with their specific preferences in terms of geography, ticket size, industry, technology or even founder profiles.
Be more inclusive. Purely data-driven approaches would suggest mirroring the past into the future as filters are based on historic data. Considering that minorities received little funding in the past, this would never change with a purely data-driven approach. Tackling this problem, VCs can empower minorities by prioritizing them accordingly in their filters.
Adapt to changing requirements. In line with the previous bullet, purely data-driven approaches would not be able to adapt to changing market dynamics. For example, ML-based approaches might tell us what a successful B2C FinTech Neobank looks like but it would struggle to identify patterns of a successful Core Fusion company as the data does not yet exist. Investors can rebalance by including their own perspectives about the future in their filters.
Dynamic, ML-based screening
Remove human bias. For example, human investors have a limited set of experience and an incomplete sample of successful companies. As a result, they would over-index these patterns and miss out on for them so far unknown success patterns. Moreover, traditional screening is impacted by similarity bias, recency bias and others. Incorporating patterns from comprehensive datasets reduces biases significantly compared to human processes.
Scalability. ML-based approaches can easily process and screen hundreds of thousands, even millions of startups in due course whereas humans would take forever to do so.
By combining the best of both worlds, we receive a single “likelihood of success score” that helps investors to cut through the noise. We can then either present all companies and leave it to the investor to sort companies based on their score and manually define a cut-off in line with the overarching filters and available resources at the time or we define a fixed score cut-off and only present the companies that qualify above. So far, so good. But how can we integrate these novel sourcing and screening approaches into existing processes to close the remaining gap between machines at the top of the funnel and human investors at the bottom of the funnel?
Traditional VC processes and frameworks
First off, let’s understand the status quo of the VC funnel. Processes and frameworks of how VCs split responsibilities among their team members are highly diverse and depend on a variety of factors. Clearly, there exist interdependencies as the focus of the fund is the sum of the focus of all individual team members. A bigger fund delivers more management fee which in turn allows to grow a bigger team which then allows every individual to specialise more. I see 5 major dimensions of focus.
Industry: DeepTech, IndustrialTech, FinTech, Logistics, Mobility etc.
Technology: AI, Blockchain, IoT, Robotics, VR/AR, web3 etc.
Business model: SaaS, marketplace, open-source, transactional etc.
Value chain: Sourcing, screening, deal assessment, deal winning, closing, portfolio work, etc.
Geography: DACH, France, UK, Nordics, Southern Europe etc.
As a rule of thumb: Smaller funds tend to be more specialised in stage (also earlier as the diversification strategy then defines the number of investments, the target shareholding and the average ticket size), geography and industry/technology/business model (think of highly specialised micro VCs or single GP funds) whereas bigger funds oftentimes go multi-stage, global and industry agnostic. In reality, few VC funds started as multi billion dollar rocket ships but rather grew over time. And so did their processes and the degree of specialization within their teams.

I define the degree of specialization on a macro and micro level as 1 minus the ratio of individual focus to fund focus, whereas the segments of the individual focus are a subset of the fund focus. To calcule the ratio on the micro level, pick the number of focus items for the individual and the fund across one of the four dimensions above. For example, individual industry focus is DeepTech and Industrial Tech (2 items) whereas the fund level industry focus is DeepTech, IndustrialTech, FinTech, Logistics and Mobility (5 items). The resulting ratio is 1- 2 : 5 = 60%. This ratio can vary across team members but should be in the same ballpark as otherwise the degree of specialization within the team is imbalanced. To calculate the ratio on the macro level, we can easily average the micro ratios for all team members per dimension and then average all four micro ratios (I know “never average the average”, but quick and dirty to get a ballpark ;))
Hereof, I’d like to share some frameworks along the most important determinant being the investment team size.
Small investment teams <5 FTE: Obvious and easy: Everyone does everything across all five dimensions. Low degree of specialization across micro and macro. Focus of the fund is rather narrow and individual team members tend to split their responsibilities, if at all, across 1. Industry, 2. Technology and/or 3. Business Model, meaning growing micro ratios across the respective dimensions. Examples include COSS Capital (strong open-source business model focus) or Inflection VC (focus on web3 and open economy).
Mid-sized investment teams 5-15 FTE: With a growing team and additional resources, the specialization continues across 1. Industry, 2. Technology and/or 3. Business Model. Sometimes across one or two dimensions, sometimes across all three. Thereafter, the next dimension for specialization becomes 4. Value Chain. For example, more junior investors might focus on sourcing and deal support whereas more senior investors focus more on assessment, deal winning and portfolio work. While many people argue that value chain specialization prevents or slows down the development of a holistic investor profile, I’d argue that long-term it makes you even better as you are able to nail one part of the job after another with 100% focus.
With four dimensions of specialization, funds typically start layering them, creating a multi-dimensional matrix of specialization. Most funds layer 4. Value chain focus with either a) 1. Industry, 2. Technology and/or 3. Business model focus, or b) 5. Geography focus. In my experience, a hybrid is the best setup, i.e. 4. & 5. = juniors split their sourcing responsibilities based on geographies and 4. & 1./2./3. = seniors split their deal assessment, winning and portfolio work responsibilities based on industry, technology and/or business model expertise.
In practice, juniors spend time on the ground of a specific geography to source every deal that is headquartered or has founders based in their region. Once sourced, they hand it over (for example via ping in CRM system) to senior industry/technology/business model expert for assessment, deal winning and closing, to then work together with the respective portfolio company. This “specialization layering” is oftentimes how deal teams evolve.
Big investment teams >15 FTE: Big teams continue “specialization layering” and increase micro ratios. They oftentimes even split up into sub teams alongside the five dimensions above. For example, a) industry/technology/business model expert groups, b) value chain based teams like investment, deal execution and portfolio value creation teams or c) geography based teams with different offices and foot on the ground. Examples include Accel, Insight, Lightspeed, Sequoia or Earlybird, to name a few.
How to marry data-driven sourcing and screening approaches with traditional VC processes?
Now that we’ve shed some light on different processes to coordinate responsibilities within a VC, let’s see how we can incorporate data-driven sourcing and hybrid screening approaches into existing coverage frameworks. Assuming we have a single source of truth CRM system that provides comprehensive startup coverage and holistic, well-balanced information about the respective companies top of the funnel, we need to map the most promising opportunities to the respective investment team members. To do this, we built an auto-tagging algorithm that automatically creates industry, technology and business model tags based on company descriptions. With the resulting tags and the existing headquarter labels in the system, VCs can then easily map the opportunities to their investment team members and ensure fluent integration.
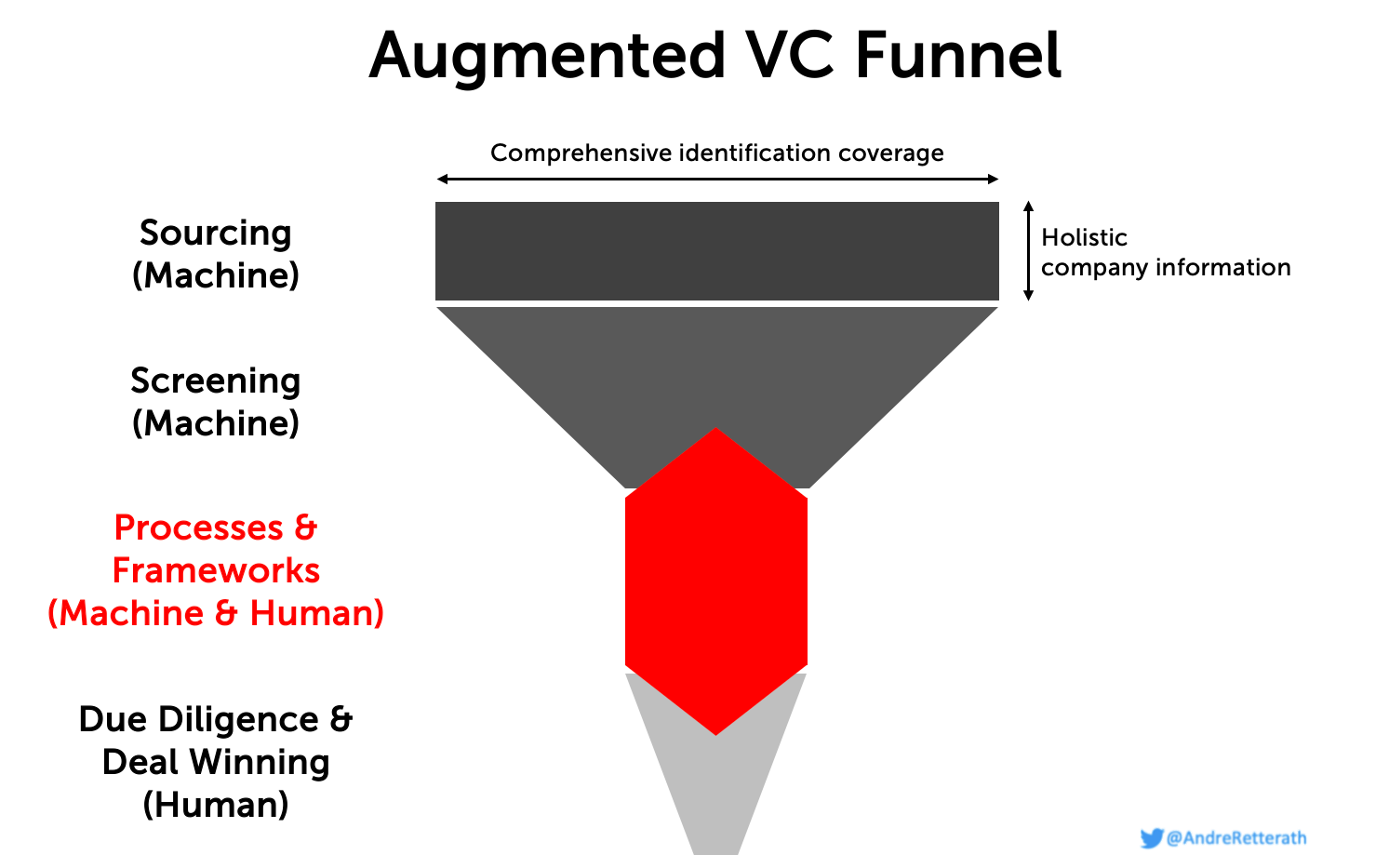
That’s it for today. Next episode, I will describe why comprehensive coverage together with efficient, effective and inclusive screening is great but not sufficient, and why firm brand together with the personal brand of the individual investor are key to ensure preferred access.
Stay driven,
Andre
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in data-driven innovation. Subscribe below and follow me on LinkedIn or Twitter to never miss data-driven VC updates again.
What do you think about my weekly Newsletter? Love it | It's great | Good | Okay-ish | Stop it
If you have any suggestions, want me to feature an article, research, your tech stack or list a job, hit me up! I would love to include it in my next edition😎